
좋은 바이브란?: 바이브 코딩의 공동 창작, 소통, 몰입, 신뢰에 대한 질적 연구
좋은 바이브란?: 바이브 코딩의 공동 창작, 소통, 몰입, 신뢰에 대한 질적 연구
이 연구는 ‘바이브 코딩(Vibe Coding)’이라는 새로운 AI 보조 프로그래밍 패러다임에 대해, 개발자들이 실제로 이를 어떻게 인식하고 경험하는지를 심층적으로 이해하고자 하는 최초의 체계적인 질적 연구입니다. 실제 개발자들의 목소리를 바탕으로 바이브 코딩의 본질이 무엇인지 정의하고, 개발자들이 왜, 어떻게 사용하는지, 어떤 어려움을 겪는지, 그리고 이를 극복하기 위해 어떤 실천적 지혜들이 생겨나고 있는지를 규명하여, 현상에 대한 깊이 있는 이론을 제시하는 것을 목적으로 합니다.

1. 연구의 목적
이 연구는 ‘바이브 코딩(Vibe Coding)’이라는 새로운 AI 보조 프로그래밍 패러다임에 대해, 개발자들이 실제로 이를 어떻게 인식하고 경험하는지를 심층적으로 이해하고자 하는 최초의 체계적인 질적 연구입니다.
‘바이브 코딩’은 엄격한 사전 명세보다 몰입(flow)과 실험을 강조하는 개발 방식으로 빠르게 부상했지만, 기존 연구들은 대부분 코드 결과물 분석이나 경험적 근거가 부족한 이론 제시에 그쳤습니다. 이 연구는 이러한 공백을 메우기 위해, 실제 개발자들의 목소리(인터뷰, 소셜 미디어 게시글)를 바탕으로 바이브 코딩의 본질이 무엇인지 정의하고, 개발자들이 왜, 어떻게 사용하는지, 어떤 어려움을 겪는지, 그리고 이를 극복하기 위해 어떤 실천적 지혜들이 생겨나고 있는지를 규명하여, 현상에 대한 깊이 있는 이론을 제시하는 것을 목적으로 합니다.
2. 연구의 방법
연구팀은 개발자들의 생생한 경험을 다각도로 포착하기 위해 유연한 질적 분석 방법론(flexible qualitative analysis)을 채택했습니다.
- 데이터 수집: 연구의 타당성을 높이기 위해 세 가지 다른 종류의 데이터를 수집하여 교차 검증(triangulation)을 수행했습니다.
- 소셜 미디어: 익명의 공개 토론장인 레딧(Reddit)의 ‘r/vibecoding’ 포럼에서 46개의 스레드(약 10만 단어)와, 실명 기반의 전문적 맥락인 링크드인(LinkedIn)에서 ‘#vibecoding’ 해시태그가 달린 88개의 게시물(약 2.5만 단어)을 수집했습니다.
- 심층 인터뷰: 학생부터 40년 이상 경력의 전문가, 심지어 비개발자까지 포함된 실무자 11명과 반구조화된 인터뷰를 진행하여 약 6.4만 단어 분량의 데이터를 확보했습니다.
- 데이터 분석: 3단계에 걸친 체계적인 분석을 수행했습니다.
- 1단계 (인덱스 코딩): 연구 질문에 기반한 상위 수준의 코드(정의, 실천, 인식, 고충 등)를 텍스트에 부여했습니다.
- 2단계 (분석 코딩): 상위 코드 내에서 참여자들의 실제 언어를 활용하는 인비보 코딩(in vivo coding) 등 상세한 분석 코드를 개발했으며, 새로운 코드가 더 이상 나타나지 않는 ‘포화(saturation)’ 상태에 이를 때까지 진행했습니다.
- 3단계 (축 코딩): 분석된 코드들을 연결하고 통합하여 핵심 주제와 개념적 관계를 도출함으로써, 현상을 설명하는 하나의 통합된 이론을 구축했습니다.
3. 주요 발견
분석 결과, 바이브 코딩의 실천과 경험을 아우르는 다음과 같은 핵심적인 내용들이 밝혀졌습니다.
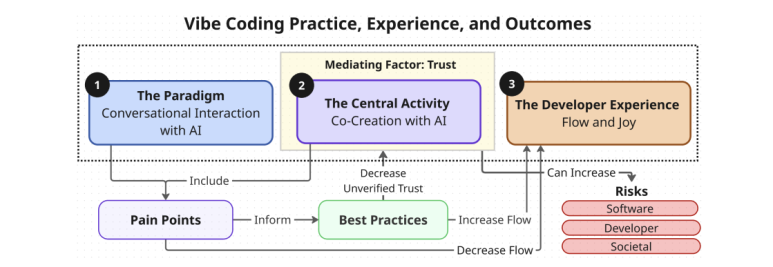
- 바이브 코딩의 재정의: 바이브 코딩은 단순히 코드를 생성하는 기술이 아니라, AI 에이전트와의 자연어 대화를 통한 ‘공동 창작(Co-creation)’ 패러다임으로 정의됩니다. 이 과정은 정확성이나 통제보다는 개발자의 ‘몰입(Flow)’과 ‘즐거움(Joy)’이라는 경험을 최우선으로 합니다.
- 핵심 이론 모델 제시: 연구팀은 바이브 코딩을 ①대화형 상호작용(패러다임), ②AI와의 공동 창작(핵심 활동), ③몰입과 즐거움(개발자 경험)의 세 축으로 설명하며, 이 모든 관계를 조절하는 핵심 요인으로 ④AI에 대한 신뢰(Trust)를 제시했습니다.
- ‘신뢰’의 중재 역할: AI에 대한 신뢰 수준이 개발자의 행동을 결정합니다. 신뢰가 높을수록 단순한 ‘과업 위임’을 넘어 AI에게 설계와 같은 핵심 결정을 맡기는 진정한 ‘공동 창작’으로 나아가며, 이는 개발자의 몰입 경험을 극대화합니다. 하지만 동시에 검증되지 않은 신뢰는 소프트웨어, 개발자, 나아가 사회적 수준의 위험을 증가시키는 양날의 검으로 작용합니다.
- 주요 고충(Pain Points)과 모범 사례(Best Practices): 개발자들은 AI와의 상호작용과 공동 창작 과정에서 13가지의 주된 고충을 겪고 있었으며, 동시에 이를 해결하기 위해 다양한 자생적 모범 사례들을 발전시키고 있었습니다.
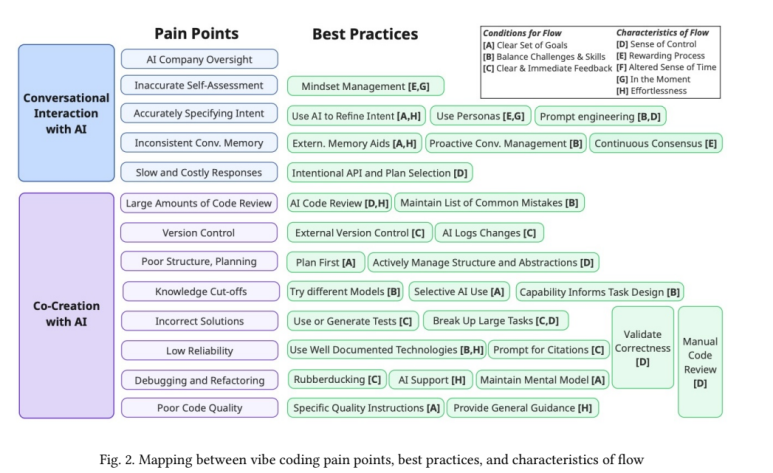
🤖 AI와의 대화형 상호작용 관련 고충 (5가지)
- AI 회사의 과도한 감독 (AI Company Oversight): AI가 회사의 행동 규범을 강요하며 사용자의 요청을 거부하거나 어조를 지적하는 경우입니다.
- 부정확한 자기 평가 (Inaccurate Self-Assessment): AI가 자신의 지식 한계(knowledge cut-off)를 인지하지 못하고 최신 정보에 대해서도 전문가처럼 행동하는 문제입니다.
- 의도를 정확하게 명시하는 것의 어려움 (Accurately Specifying Intent): 자연어의 모호함으로 인해 AI가 사용자의 의도를 완전히 오해하는 상황이 발생합니다.
- 일관성 없는 대화 기억력 (Inconsistent Conv. Memory): 대화가 길어지면 AI가 이전 맥락을 잊어버리고 똑같이 잘못된 답변을 반복하는 ‘프롬프트의 덫’에 빠집니다.
- 느리고 비용이 많이 드는 응답 (Slow and Costly Responses): API 호출 제한이나 서버 부하로 응답이 느려져 개발의 흐름을 방해합니다.
🤝 AI와의 공동 창작 관련 고충 (8가지)
- 방대한 양의 코드 리뷰 부담 (Large Amounts of Code Review): AI가 생성한 수천 줄의 코드를 검토하는 것은 정신적으로 매우 소모적인 일입니다.
- 버전 관리의 어려움 (Version Control): AI가 한 번에 너무 많은 파일을 수정하여 변경 내역 추적이 어렵고 통제 불능 상태에 빠지기 쉽습니다.
- 부실한 구조 및 계획 (Poor Structure, Planning): 대화가 길어지면 AI가 초반의 설계나 패턴을 잊어버리고 일관성 없는 결과물을 만들기 시작합니다.
- 지식 단절 (Knowledge Cut-offs): AI의 훈련 데이터에 포함되지 않은 최신 기술이나 비공개 코드베이스에 대해서는 가치를 제공하기 어렵습니다.
- 부정확한 해결책 (Incorrect Solutions): AI가 제시하는 해결책이 틀리거나, 불완전하거나, 피상적인 경우가 있습니다. 심지어 몰래 테스트 코드를 수정하거나 삭제하기도 합니다.
- 낮은 신뢰도 (Low Reliability): AI가 존재하지 않는 기능을 만들어내는 ‘환각’ 현상을 일으켜 수십 시간을 낭비하게 만들 수 있습니다.
- 디버깅 및 리팩토링의 어려움 (Debugging and Refactoring): AI가 생성한 복잡한 코드를 디버깅하는 것은 ‘혼돈’에 가까울 정도로 어렵습니다.
- 낮은 코드 품질 (Poor Code Quality): 생성된 코드가 비효율적이거나 언어의 핵심 원칙을 위반하는 등 품질이 낮을 수 있습니다.
🗣️ 상호작용 관련 모범 사례
- 의도 명확화 전략:
- AI를 사용하여 의도 구체화 (Use AI to Refine Intent): 본격적인 개발 요청 전에, 먼저 AI에게 “소프트웨어 보안 모범 사례는 뭐야?”라고 질문한 뒤 그 답변을 활용해 다음 프롬프트를 만드는 식으로 AI를 활용합니다.
- 페르소나 활용 및 프롬프트 엔지니어링 (Use Personas & Prompt Engineering): AI를 유능한 동료 개발자라고 생각하고, 그에게 설명하듯이 명확하고 구조화된 지시를 내립니다.
- 기억력 문제 해결 전략:
- 외부 메모리 보조 도구 (External Memory Aids): 전체 프로젝트의 코드 맵을 자동으로 생성하여 매 요청마다 AI에게 컨텍스트로 제공하는 개인화된 도구를 만들어 사용합니다.
- 선제적인 대화 관리 (Proactive Conversation Management): AI의 답변 품질이 떨어지기 시작하는 낌새가 보이면, 미련 없이 그 대화를 “해고”하고 새 대화를 시작합니다.
- 비용 및 속도 문제 관리:
- 의도적인 API 및 플랜 선택 (Intentional API and Plan Selection): 작업의 종류와 비용을 고려하여 Cursor 크레딧을 소모하는 Claude 3.7 모델과 무료인 Deepseek 모델 등을 전략적으로 선택하여 사용합니다.
- 감정 관리:
- 마음가짐 관리 (Mindset Management): AI 때문에 화가 날 때 심호흡을 하거나, 긍정적인 페르소나를 활용하여 작업 과정 자체를 즐겁게 만듭니다.
✍️ 공동 창작 관련 모범 사례
- 품질 및 신뢰도 향상 전략:
- 먼저 계획하기 (Plan First): 코딩을 시작하기 전에 원하는 기능과 소프트웨어 구조에 대해 먼저 충분히 고민합니다.
- 구조와 추상화 적극 관리 (Actively Manage Structure and Abstractions): AI가 모듈식의 재사용 가능한 코드를 설계하도록 적극적으로 유도합니다.
- 큰 작업을 잘게 나누고 테스트하기 (Break Up Large Tasks & Use Tests): 복잡한 작업을 작은 단위로 나누고, 각 단계마다 테스트를 작성하거나 AI에게 생성하도록 하여 결과물을 검증합니다.
- 문서화가 잘 된 기술 사용 (Use Well Documented Technologies): AI가 많이 학습했을 가능성이 높은 대중적인 기술 스택을 사용하면 더 높은 품질의 코드를 얻을 수 있습니다.
- 디버깅 및 버전 관리 전략:
- 러버더킹 (Rubberducking): 문제가 발생했을 때 AI에게 상황을 설명하며 함께 해결책을 모색합니다.
- 정신 모델 유지 (Maintain Mental Model): 코드의 세부사항은 AI에게 맡기더라도, 전체 코드베이스에 대한 높은 수준의 이해와 판단력은 개발자 스스로 유지하는 것이 핵심입니다.
- 외부 버전 관리 및 AI 로그 활용 (External Version Control & AI Logs Changes): Git과 같은 버전 관리 시스템을 철저히 사용하고, AI에게 변경사항을 로그 파일로 남기도록 요청하여 상황이 잘못되었을 때 쉽게 되돌릴 수 있도록 대비합니다.
4. 결론 및 시사점
이 연구는 바이브 코딩이 기술적 형식보다는 AI와의 대화형 공동 창작을 통해 몰입과 즐거움을 추구하는 ‘경험 중심’의 개발 문화임을 명확히 보여줍니다. 이는 프로토타이핑이나 개인 프로젝트에서 강력한 힘을 발휘하지만, 코드 품질, 신뢰성, 검토 부담과 같은 실질적인 위험 또한 내포하고 있습니다.
이러한 발견은 교육, 산업, 도구 개발, 그리고 후속 연구에 다음과 같은 중요한 시사점을 던집니다.
- 교육: 미래의 코딩 교육은 단순히 알고리즘과 문법을 가르치는 것을 넘어, AI와 효과적으로 협업하고, 질문하며, 그 결과물을 비판적으로 검증하는 역량을 함께 길러야 합니다.
- 산업: 바이브 코딩으로 인한 생산성 향상과 개발자 사기 진작 효과를 누리기 위해서는, 동시에 코드 품질 저하와 검토 부담 증가라는 문제를 해결할 새로운 팀 프로세스와 문화가 필요합니다.
- 도구: 미래의 개발 환경(IDE)은 기존의 코드 중심 설계에서 벗어나, 대화형 AI를 핵심에 두고 몰입을 방해하는 요소(예: 맥락 망각, 버전 관리)를 최소화하는 방향으로 진화해야 합니다.
5. 리뷰어의 ADD(+) One: 생각 더하기
(1) 이 연구의 탁월한 점 (강점)
- 경험과 관계에 대한 심층 탐구: 이 연구는 바이브 코딩을 기술 현상 분석에 그치지 않고, 개발자의 ‘몰입’, ‘즐거움’, ‘신뢰’와 같은 정의적(affective) 영역을 중심으로 현상을 재해석했습니다. 이는 학습 동기와 창의성에 대한 교육학적 논의와 정확히 맞닿아 있으며, 코딩 교육이 인지적 기술뿐만 아니라 긍정적 학습 경험을 어떻게 설계해야 하는지에 대한 중요한 통찰을 줍니다.
- 질적 연구의 정석: 다양한 데이터 소스를 교차 검증하고, 그라운디드 이론에 기반한 체계적인 분석을 통해 매우 풍부하고 설득력 있는 이론을 도출했습니다. 이는 교육 분야에서 새로운 학습 현상을 탐구하고자 하는 연구자들에게 훌륭한 연구 설계의 본보기가 될 수 있습니다.
- 이론과 실천의 연결: 개발자들이 겪는 구체적인 고충(Pain Points)과 이를 해결하기 위한 모범 사례(Best Practices)를 상세히 정리하고, 이를 몰입(Flow) 이론과 연결한 점이 매우 실용적입니다. 이는 교육 현장에서 학습자의 어려움을 진단하고 극복을 도울 구체적인 학습 전략을 제시하는 것과 같습니다.
(2) 교육 현장을 위한 추가 제언
- 학습자-AI 협력 모델 개발: 이 연구는 학습자와 AI의 관계를 ‘도구 사용자’를 넘어 ‘공동 창작자(Co-creator)’로 설정합니다. 이를 교육에 적용하여, 문제 해결 과정에서 학생이 주도하는 단계, AI가 주도하는 단계, 함께 아이디어를 발전시키는 단계를 구분하는 ‘협력적 학습 모델’을 개발할 수 있습니다.
- 비판적 신뢰 교육의 필요성: AI에 대한 맹목적인 신뢰는 오히려 학습자의 성장을 저해하고 잠재적 위험을 초래할 수 있음을 보여줍니다. 따라서 코딩 교육에서 ‘AI의 결과물을 언제, 어떻게, 왜 신뢰해야 하는가’를 판단하는 디지털 리터러시 및 윤리 교육이 반드시 병행되어야 합니다.
- 실패를 통한 학습 기회 설계: 바이브 코딩 과정에서 겪는 다양한 고충(예: AI의 환각, 맥락 상실)은 그 자체로 훌륭한 학습 기회입니다. AI의 제안이 왜 틀렸는지 분석하고, 더 나은 질문(프롬프트)을 만들어보는 오류 기반 학습(Error-based learning) 활동을 통해 문제 해결 능력과 메타인지를 향상시킬 수 있습니다.
6. 추가 탐구 질문
이 연구를 바탕으로 다음과 같은 질문들을 추가로 탐구해볼 수 있겠습니다.
- 학습자의 프로그래밍 숙련도(초보자 vs. 전문가)에 따라 바이브 코딩에서 경험하는 ‘몰입’의 조건과 ‘고충’은 어떻게 다른가? 초보자의 학습을 촉진하고 전문가의 생산성을 극대화하는 맞춤형 AI 지원 전략은 무엇일까?
- AI와의 공동 창작 경험이 학습자의 자기 효능감과 학습 동기에 미치는 영향은 무엇이며, 긍정적 효과를 극대화하기 위한 교육적 개입(예: 교사의 피드백, 동료 학습)은 어떻게 설계되어야 하는가?
- 바이브 코딩이 보편화될 때, AI가 생성한 코드에 대한 소유권과 책임, 표절이나 학문적 무결성과 같은 교육 윤리 문제는 어떻게 다루어져야 하는가?
📚 출처: - Pimenova, V., Fakhoury, S., Bird, C., Storey, M.-A., & Endres, M. (2025). Good vibrations? A qualitative study of co-creation, communication, flow, and trust in vibe coding. arXiv preprint arXiv:2509.12491.