
구술 샘플링(Verbalized Sampling)으로 LLM 다양성 잠금현상 해제하기
구술 샘플링(Verbalized Sampling)으로 LLM 다양성 잠금현상 해제하기
1. 연구의 목적
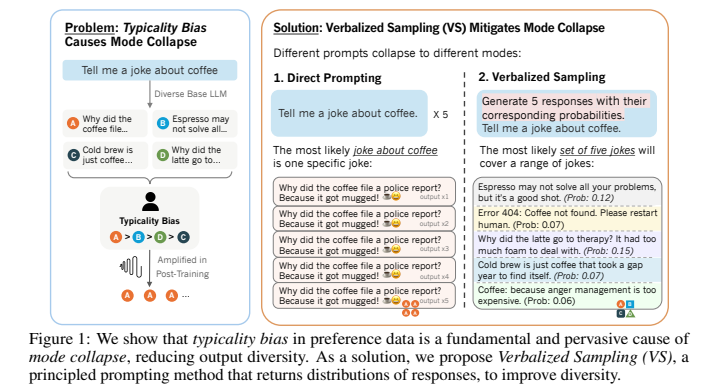
본 연구는 대규모 언어 모델(LLM)이 정렬(alignment) 학습 후 결과물이 획일화되는 모드 붕괴(mode collapse) 현상의 근본 원인을 탐구합니다. 연구진은 이 현상이 기존에 알려진 알고리즘의 한계 때문이 아니라, 인간 평가자가 익숙하고 전형적인 텍스트를 선호하는 전형성 편향(typicality bias)이라는 데이터 차원의 문제임을 규명하고자 합니다.
이에 대한 해결책으로, 별도의 모델 학습 없이 프롬프팅 방식의 변경만으로 모드 붕괴를 완화하고 LLM의 잠재적 다양성을 효과적으로 끌어낼 수 있는 언어화된 샘플링(Verbalized Sampling, VS) 기법을 제안하고 그 효과를 종합적으로 검증하는 것을 핵심 목적으로 삼고 있습니다.

2. 연구의 방법
연구 목적을 달성하기 위해 이론, 데이터 분석, 대규모 실험을 결합한 다각적인 접근법을 사용했습니다.
- 이론적 분석: 보상 모델을 활용하여 전형성 편향을 수학적으로 모델링하고, 이 편향이 RLHF(인간 피드백 기반 강화학습) 최적화 과정에서 어떻게 모델의 결과물 분포를 특정 소수 응답에 집중시켜 모드 붕괴를 유발하는지 이론적으로 증명했습니다.
- 경험적 검증: HELPSTEER와 같은 실제 인간 선호도 데이터셋을 분석하여, 응답의 정답 여부와 무관하게 인간 평가자가 사전 학습 모델에 더 전형적인(typical) 텍스트를 선호하는 경향이 통계적으로 유의미하게 존재함을 실증적으로 보였습니다.
- 포괄적 실험: 제안하는 VS 기법의 효과를 검증하기 위해, GPT, Gemini, Claude 등 다양한 최신 LLM들을 대상으로 창의적 글쓰기(시, 이야기, 농담), 대화 시뮬레이션, 개방형 질의응답(Open-Ended QA), 합성 데이터 생성 등 광범위한 태스크에 걸쳐 기존 프롬프팅 방식들과 성능을 비교했습니다.
- 평가: 의미적/어휘적 다양성, 정답률, 커버리지 등 자동 평가 지표와 인간 평가를 함께 사용하여 제안 기법의 다양성 및 품질 개선 효과를 종합적으로 측정했습니다.
3. 주요 발견
(1) 데이터에 내재된 전형성 편향 확인
인간 선호도 데이터에는 정답 여부와 별개로, 단순히 익숙하고 일반적인 표현을 선호하는 전형성 편향이 내재되어 있으며, 이것이 모드 붕괴를 일으키는 핵심 원인임을 경험적으로 확인했습니다.
(2) VS 기법의 압도적인 다양성 향상
단순히 하나의 답변을 요구하는 대신, “커피에 대한 농담 5개와 각각의 확률을 생성해 줘”와 같이 여러 답변과 그 확률을 함께 요구하는 VS 기법은 기존 프롬프팅 방식 대비 모든 창의적 글쓰기 과제에서 1.6배에서 2.1배 더 높은 다양성을 보이며 모드 붕괴 현상을 효과적으로 완화했습니다.
(3) 품질 저하 없는 성능 개선
VS는 다양성을 크게 높이면서도 답변의 품질, 사실적 정확성, 안전성을 저해하지 않았습니다. 특히 VS-CoT(사고의 연쇄와 결합)와 같은 파생 기법은 다양성과 품질을 동시에 개선하는 파레토 최적(Pareto optimal) 결과를 보였습니다.
(4) 더 뛰어난 모델에서 더 큰 효과
GPT-4.1과 같은 고성능 대형 모델일수록 VS 기법을 통한 다양성 향상 효과가 더 크게 나타나는 창발적 경향(emergent trend)을 발견했습니다. 이는 VS가 뛰어난 모델의 잠재력을 더 효과적으로 이끌어냄을 시사합니다.
(5) 조절 가능한 다양성
프롬프트에 확률 임계값(예: “확률이 0.1 이하인 답변만 생성”)을 명시하는 것만으로 생성되는 결과물의 다양성 수준을 세밀하게 조절할 수 있음을 입증했습니다.
4. 결론 및 시사점
- 본 연구는 LLM의 모드 붕괴가 알고리즘만의 문제가 아니라, 정렬 학습에 사용되는 인간 선호도 데이터의 전형성 편향에서 비롯된 근본적인 문제임을 설득력 있게 제시합니다. 제안된 언어화된 샘플링(VS)은 이 문제를 해결하는 간단하면서도 강력한 추론 시점의 해결책입니다.
- LLM 정렬 문제를 데이터 중심적 관점에서 새롭게 조명했다는 점에서 중요한 의의를 가집니다. 특히 재학습 없이 프롬프팅의 변화만으로 모델의 내재된 다양성을 복원할 수 있음을 보여줌으로써, 향후 더 창의적이고 탐색적인 LLM 응용(예: 가설 생성, 사회 시뮬레이션, 고품질 합성 데이터 생성 등)의 가능성을 열어줍니다.
5. 리뷰어의 ADD(+) One: 생각 더하기
(1) 이 연구의 탁월한 점 (강점)
- 근본적인 원인 규명: 모드 붕괴의 원인을 알고리즘에서 데이터 편향으로 전환하여 문제의 본질을 파고든 통찰력이 매우 뛰어납니다. 이는 문제에 대한 이해의 지평을 넓히는 중요한 개념적 기여입니다.
- 간결하고 실용적인 해결책: 학습이나 모델의 로짓(logits) 접근 없이 프롬프트 수정만으로 문제를 해결하는 VS 기법은 매우 우아하고 실용적이며, 모든 LLM에 즉시 적용할 수 있다는 점에서 파급력이 큽니다.
- 탄탄한 검증 과정: 이론적 모델링, 데이터셋 분석, 광범위한 최신 모델 대상 실험, 인간 평가까지 이어지는 철저하고 종합적인 검증 과정이 연구의 신뢰도를 크게 높입니다.
(2) 추가 제언 및 비판점
- 데이터 수집 패러다임 전환 제언: 전형성 편향의 발견은 향후 LLM 정렬을 위한 데이터 수집 방식을 근본적으로 재고해야 함을 시사합니다. 평가자에게 단순히 더 나은 응답이 아닌, 더 새롭고 창의적인 응답에도 가치를 부여하도록 가이드라인을 수정할 필요가 있습니다.
- 비용 문제: 저자들이 인정한 바와 같이, 여러 개의 후보를 생성하는 VS는 단일 응답 생성보다 추론 비용(시간, 토큰)이 더 높습니다. 실제 서비스 적용을 위한 비용-효과성 분석이 보완될 필요가 있습니다.
- 언어화된 확률의 신뢰성: 모델이 제시하는 확률 값이 실제 모델의 내부 신뢰도를 얼마나 정확하게 반영하는지에 대한 추가적인 탐구가 필요합니다. 이는 모델의 생성된 텍스트일 뿐, 진정한 의미의 확률적 계산 결과는 아니기 때문입니다. 이 확률의 보정(calibration)에 대한 연구는 흥미로운 후속 연구가 될 수 있습니다.
6. 추가 탐구 질문
- 전형성 편향은 길이 편향, 동조 편향 등 다른 알려진 데이터 편향과 어떻게 상호작용하며, VS가 이러한 다른 편향들도 완화할 수 있는가?
- VS 기법을 추론 시점이 아닌 학습 과정에 통합할 수 있는가? 예를 들어, VS 프롬프트에 대해 더 다양하고 정확한 분포를 생성하도록 모델을 미세조정하는 방식이 가능할까?
- VS가 생성하는 다양한 결과물을 강화학습(RL)의 탐색(exploration) 전략에 활용한다면, 에이전트의 성능을 얼마나 향상시킬 수 있는가?
출처: Zhang, J., Yu, S., Chong, D., Sicilia, A., Tomz, M. R., Manning, C. D., & Shi, W. (2025). Verbalized sampling: How to mitigate mode collapse and unlock LLM diversity. https://arxiv.org/abs/2510.01171