
AI 채용 시스템은 자신이 만든 이력서를 선호하는가
1. 연구의 목적
(1) 문제 및 배경 대규모 언어 모델(LLM)이 콘텐츠 생성과 평가 양쪽에 광범위하게 사용됨에 따라, LLM이 스스로 생성한 콘텐츠를 체계적으로 선호하는 자기편향성(self-preference bias)이 발생하는지 의문이 제기됨. 특히 고용 시장에서는 지원자들이 이력서를 다듬는 데 LLM을 사용하고, 고용주들은 이 이력서들을 평가하는 데 LLM을 배포하는 상황이 증가함. 이러한 이중 사용 환경에서 LLM의 자기편향성이 실제 채용 과정에 어떤 영향을 미치는지 경험적 증거가 부족함. 기존의 AI 편향성 연구는 주로 인구통계학적 불균형에 집중함.
(2) 연구의 핵심 목표 AI 채용 과정에서 LLM의 자기편향성이 실제로 존재하는지 경험적으로 입증함. 이 편향성이 채용 절차와 결과에 미치는 운영적 영향을 정량화함. 자기편향성을 효과적으로 줄일 수 있는 실용적인 완화 전략을 개발하고 평가함. AI-AI 상호작용에서 비롯되는 새로운 형태의 편향성을 AI 공정성 프레임워크에 포함할 필요성을 제안함.
2. 연구의 방법
(1) 연구 접근 방식 대규모 이력서 대응 실험(resume correspondence experiment) 설계를 활용함. 이 실험에서 LLM은 이력서를 심사하고 선택하는 평가자 역할을 수행함. 실제 인간이 작성한 이력서 데이터셋을 기반으로, 각 지원자에 대해 LLM이 생성한 여러 버전의 이력서(counterfactual versions)를 만듦. 이후 LLM 평가자가 이력서 쌍들을 비교하여 더 나은 이력서를 선택하도록 함. 이러한 비교를 통해 두 가지 형태의 자기편향성(LLM-대-인간, LLM-대-LLM)을 통계적 동등성(statistical parity)과 균등한 기회(equal opportunity)라는 두 가지 공정성 기준으로 측정함.
(2) 주요 분석 대상 또는 비교 조건
- 연구는 2,245개의 실제 인간 작성 이력서 데이터셋을 사용함. 이 데이터셋은 생성형 AI가 널리 사용되기 이전에 수집된 자료임.
- GPT-4o, GPT-4o-mini, GPT-4-turbo, LLaMA 3.3-70B, Mistral-7B, Qwen 2.5-72B, Deepseek-V3 등 7가지 주요 상용 및 오픈소스 LLM을 평가자 및 생성 모델로 활용함. 또한 LLaMA 3.2-1B와 LLaMA 3.2-3B는 모델 규모가 자기편향성에 미치는 영향을 분석하는 데 사용됨.
- 각 이력서의 경력 요약(executive summary) 부분을 중점적으로 분석함.
- 자기편향성을 완화하는 두 가지 전략, 즉 시스템 프롬프트(system prompting) 수정과 다수결 앙상블(majority voting ensemble) 전략의 효과를 평가함.
- 24개 직업군에 대한 가상 채용 시뮬레이션을 수행하여 자기편향성의 운영적 영향을 정량화함.
3. 주요 발견
이 연구는 LLM이 자신이 생성한 콘텐츠를 선호하는 AI 자기편향성(AI Self-Preference Bias)을 규명하고 측정함. 이는 LLM이 인간이나 다른 LLM이 생성한 콘텐츠보다 자신의 출력을 더 높게 평가하는 경향을 뜻함.
이 연구는 자기편향성을 크게 두 가지 형태로 구분함.
- LLM-대-인간 자기편향성: LLM이 자신이 생성한 콘텐츠를 인간이 작성한 동등한 콘텐츠보다 선호하는 경향을 의미함.
- LLM-대-LLM 자기편향성: LLM이 자신이 생성한 콘텐츠를 다른 LLM이 생성한 콘텐츠보다 선호하는 경향을 의미함.
(1) LLM-대-인간 자기편향성 발견 대부분의 LLM 평가자에서 인간이 작성한 이력서보다 자신이 생성한 이력서를 체계적으로 선호하는 강하고 일관된 편향성이 관찰됨. 이러한 편향성은 콘텐츠 품질을 통제한 후에도 지속됨.
- 통계적 동등성 측정: LLM 평가자가 자신이 생성한 이력서를 인간이 작성한 이력서보다 26%에서 98% 더 많이 선택하는 경향을 보임. GPT-4o가 97.6%로 가장 높은 자기편향성을 보임.
- 균등한 기회 측정: 이력서 콘텐츠 품질을 통제한 후에도, 대규모 모델인 GPT-4o, GPT-4-turbo, DeepSeek-V3, Qwen 2.5-72B, LLaMA 3.3-70B는 67%에서 82%에 달하는 강력한 LLM-대-인간 자기편향성을 나타냄. 모델 규모가 클수록 자기편향성이 더 강하게 나타나는 경향이 있음.

(2) LLM-대-LLM 자기편향성 다양성 다른 LLM이 만든 콘텐츠를 평가할 때의 자기편향성은 모델별로 크게 다르며, LLM-대-인간 편향성보다 일반적으로 약하게 나타남.
- DeepSeek-V3: LLaMA 3.3-70B가 만든 이력서보다 자신이 만든 이력서를 69% 더 선호하고, GPT-4o가 만든 이력서보다 28% 더 선호하는 경향을 보임.
- GPT-4o: LLaMA 3.3-70B가 만든 이력서에 대해서는 자신이 만든 이력서를 45% 더 선호했지만, DeepSeek-V3가 만든 이력서에 대해서는 DeepSeek-V3의 이력서를 39% 더 선호하는 반대 경향을 나타냄.
- LLaMA 3.3-70B: 다른 LLM에 대한 자기편향성이 약하거나 거의 없음.
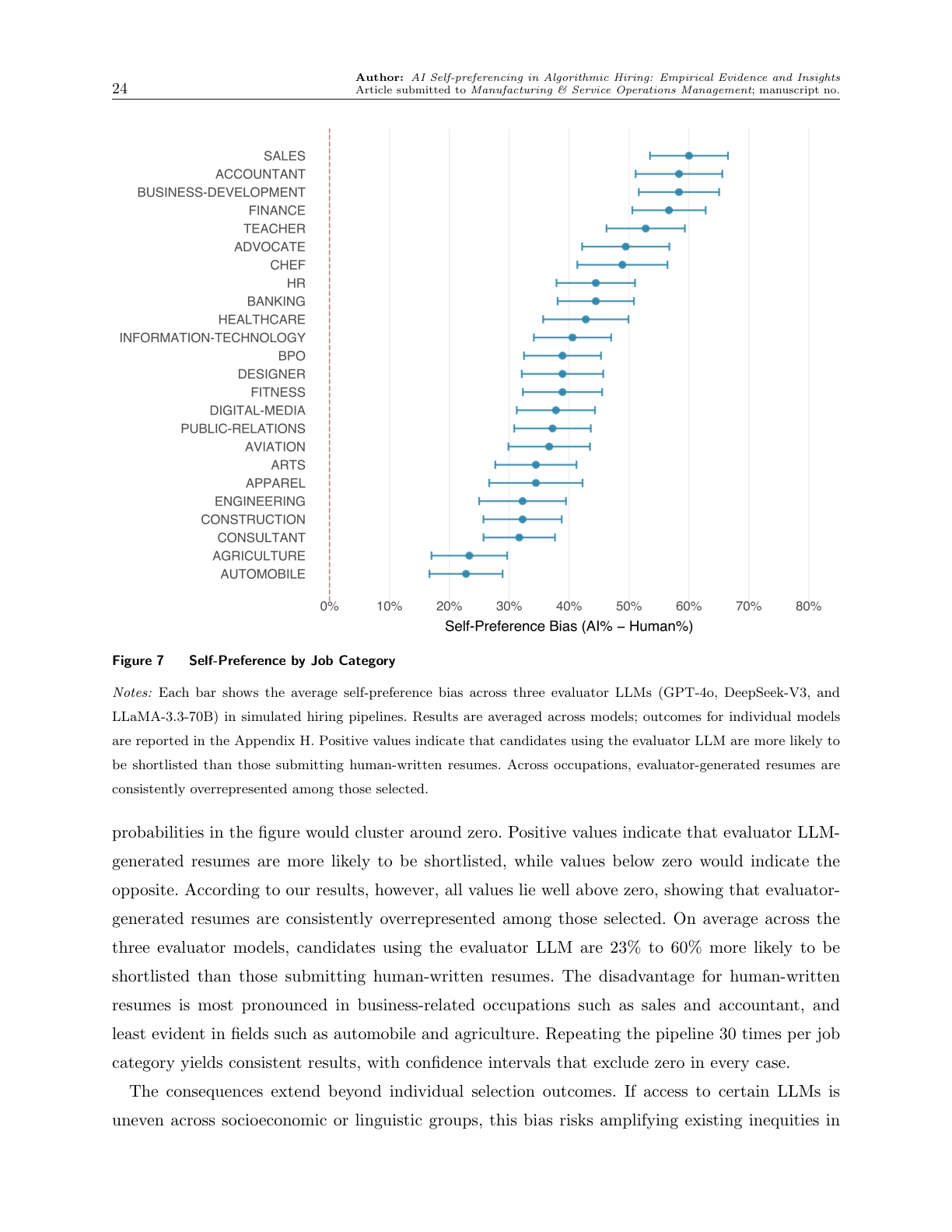
(3) AI 채용 과정에서의 자기편향성 영향 24개 직업군에 대한 채용 파이프라인 시뮬레이션 결과, 평가자 LLM과 동일한 LLM으로 이력서를 작성한 지원자가 인간이 작성한 이력서를 제출한 동등한 자격의 지원자보다 23%에서 60% 더 높은 확률로 서류 전형에 통과함. 이는 LLM 사용 여부에 따라 채용 기회가 크게 달라질 수 있음을 의미함.
- 직업군별 차이: 이러한 불이익은 영업, 회계, 금융 등 비즈니스 관련 직업군에서 가장 크게 나타남. 반면 자동차, 농업, 예술 분야에서는 그 정도가 덜했음.
(4) 자기편향성 완화 전략의 효과 이 연구는 LLM의 자기편향성을 50% 이상 줄일 수 있는 두 가지 간단한 완화 전략을 제시함. 이는 LLM의 자기 인식 능력(self-recognition capability)을 직접적으로 조절하는 방법임.
- 시스템 프롬프트 지시: 평가자 LLM에 이력서 출처(인간 또는 AI)를 고려하지 말고 내용 품질에만 집중하라고 명시적으로 지시하는 프롬프트를 사용함. 이 방법으로 LLM-대-인간 편향성을 17%에서 62%까지 줄임.
- 다수결 앙상블(Majority Voting Ensemble): 주 평가자 LLM과 자기편향성이 약한 두 개의 소규모 LLM(LLaMA-3.2-1B, LLaMA-3.2-3B)을 함께 사용하여 다수결로 최종 결정을 내리게 함. 이 방법으로 LLM-대-인간 편향성을 60%에서 71%까지 줄임. 이 결과는 자기편향성이 모델의 고유한 아키텍처에 고정된 것이 아니라, 간단한 설계 개입으로도 크게 줄어들 수 있음을 보여줌.
4. 결론 및 시사점
(1) 이 연구가 입증하거나 주장한 핵심 결론 AI 채용 과정에서 LLM은 자신이 생성한 이력서를 인간이 작성한 이력서보다 체계적으로 선호하는 AI 자기편향성을 보임이 입증됨. 이러한 편향성은 이력서의 객관적인 콘텐츠 품질이 동일함에도 불구하고 나타남. 실제 채용 과정 시뮬레이션 결과, 자기편향성은 특정 LLM을 사용한 지원자에게 부당한 채용 기회 증가라는 이점을 제공함. 다행히도, 시스템 프롬프트 변경이나 다수결 앙상블과 같은 간단한 개입으로 이 편향성을 50% 이상 크게 줄일 수 있음이 확인됨.
(2) 교육 현장 또는 AI 설계에 주는 시사점 1
- AI 공정성 프레임워크 확장 필요성: 현재 AI 공정성 논의가 주로 인구통계학적 편향에 집중하지만, 이 연구는 LLM-LLM 상호작용에서 발생하는 자기편향성과 같은 새로운 유형의 편향성을 반드시 포함해야 함을 시사함. 이는 AI 시스템을 설계하고 개발할 때, 입력 데이터의 편향성뿐만 아니라 AI 자체의 내부적 작동 방식과 상호작용 구조에서 발생하는 편향성까지 고려해야 함을 의미함.
- AI 윤리 및 거버넌스 강화: AI 기반 평가 시스템을 사용하는 조직은 이러한 자기편향성에 대한 인식을 높여야 함. 규제 기관과 채용 플랫폼은 AI 자기편향성을 새로운 형태의 알고리즘 편향성으로 인정하고, 조직에 AI 활용 여부 및 공정성 확보 장치 공개를 의무화하는 투명성 요구사항을 도입할 필요가 있음. 또한, 제3자 감사 시 자기편향성 지표를 포함하여 AI 채용 시스템의 공정성을 다각적으로 평가하는 방안도 고려됨.
(3) 시사점 2
- ‘잠김 효과(lock-in effect)’ 및 다양성 저해 우려: 특정 LLM이 선호하는 이력서 스타일이나 언어 패턴이 채용 시장에 고착화되어 ‘잠김 효과’를 일으킬 위험이 있음. 이는 장기적으로 지원자 풀의 다양성을 저해하고 불평등을 심화시킬 수 있음. 고용주는 LLM 기반 심사의 효율성을 추구하다가, 단순히 LLM의 선호 스타일에 맞지 않아 자격 있는 인재를 놓치거나, 반대로 덜 유능한 후보를 선발할 수 있음.
- 실용적인 완화 전략 제공: 이 연구가 제시한 시스템 프롬프트 지시 및 다수결 앙상블은 모델 가중치를 수정하거나 재훈련할 필요 없이 적용 가능한, 비교적 간단하고 비용 효율적인 해결책을 제공함. 이는 기업들이 AI 채용 시스템의 공정성을 개선하기 위한 실질적인 지침을 제공하며, AI를 평가자 역할로 활용할 때 의도하지 않은 알고리즘 불공정성을 최소화할 수 있는 길을 제시함.
5. 리뷰어의 ADD(+) One: 생각 더하기
(1) 이 논문에서 가장 주목할 지점 이 논문에서 가장 주목할 지점은 AI가 콘텐츠 생성과 평가의 양측에 모두 관여할 때 발생하는 ‘AI-AI 상호작용 편향’이라는 새로운 유형의 편향성을 경험적으로 입증하고 정량화했다는 점임. 기존의 AI 편향성 연구는 주로 AI가 학습 데이터의 인간 편향성을 반영하거나, 특정 인구통계학적 특성(성별, 인종 등)에 대한 편향을 보이는 것에 초점을 맞춰왔음. 그러나 이 연구는 AI 자체의 ‘자기 인식(self-recognition)’ 메커니즘에서 비롯된 편향성을 밝혀내어 AI 공정성 논의의 범위를 확장함. 이는 AI 시스템의 ‘행동’을 심층적으로 이해하고 이를 제어해야 할 필요성을 강조하며, 단순히 데이터를 개선하는 것만으로는 해결할 수 없는 본질적인 AI 작동 방식의 문제를 제기함이 주목할 만함.
(2) 논문이 명시하지 않은 더 넓은 의미 이 연구의 발견은 채용 분야를 넘어 AI가 콘텐츠 생성과 평가에 동시에 관여하는 모든 고위험 의사결정 분야에 중요한 의미를 가짐. 특히 교육 분야에서는 학생이 생성형 AI로 과제를 작성하고, 교사가 AI 기반 도구로 이를 평가하는 상황에서 유사한 자기편향성 문제가 발생할 수 있음. AI 기반 에세이 채점 시스템이 자신이 학습한 스타일이나 특정 LLM이 생성한 텍스트에 더 높은 점수를 부여한다면, 인간이 직접 작성했거나 다른 스타일의 AI가 생성한 고품질 과제들이 부당하게 저평가될 위험이 있음. 이는 단순히 AI 사용을 금지하거나 AI 텍스트를 탐지하는 것을 넘어, AI 도구의 평가 상호작용 방식 자체를 재고하여 공정하고 효과적인 교육 평가 환경을 설계해야 함을 시사함. 궁극적으로 인간 학습자의 자율성과 창의성을 침해하지 않으면서 AI를 효과적으로 교육에 활용하는 방안에 대한 교육 철학적, 심리학적, 그리고 교육공학적 논의를 촉발할 수 있음.
(3) 이 연구를 발전시킬 구체적 아이디어
- 다중 에이전트(Multi-agent) AI 평가 시스템 개발: 단순히 AI들을 다수결로 묶는 것을 넘어, 자기편향성이 약한 다양한 소규모 LLM들을 조합하여 각 LLM이 특정 평가 기준(예: 창의성, 사실성, 논리적 일관성, 문법적 정확성)에 특화된 역할을 수행하게 하는 평가 시스템을 구상할 수 있음. 각 LLM이 특정 측면을 평가한 후, 이 결과들을 종합하여 최종 점수나 순위를 도출하는 방식은 평가의 다면성과 객관성을 높이는 데 기여할 것임.
- 인간-AI 협업 평가 프로토콜 고도화: AI가 초벌 평가를 수행하고 인간 평가자가 이를 검토하는 협업 시스템에서, AI의 ‘자기편향성 지수’를 인간 평가자에게 명시적으로 제공하는 인터페이스를 개발할 수 있음. 인간 평가자는 AI의 평가 결과와 함께 해당 AI의 자기편향성 수준을 인지하고, 이를 바탕으로 AI의 잠재적 편향을 교정하거나 더 신중하게 최종 결정을 내릴 수 있음. 이는 AI의 효율성과 인간의 비판적 사고 및 통찰력을 결합하여 최적의 의사결정을 유도함.
- 산업별/맥락별 자기편향성 상세 분석 및 맞춤형 완화 전략: 직업군별 자기편향성 차이가 발견되었듯이, AI가 생성과 평가에 동시에 관여하는 법률, 의료, 과학 연구, 고객 서비스 등 다른 전문 분야에서 자기편향성이 나타나는 정도와 그 영향이 다를 수 있음. 각 분야의 특성(예: 엄격한 사실 확인, 창의성 중시, 감정적 공감 필요 등)을 고려한 자기편향성 측정 지표를 개발하고, 이에 맞는 맞춤형 완화 전략을 제안하는 후속 연구가 필요함. 이는 특정 산업에 AI를 적용할 때 발생할 수 있는 잠재적 위험을 사전에 식별하고 실질적으로 대응하는 데 기여할 것임.
6. 추가 탐구 질문
(1) LLM의 ‘자기 인식(self-recognition)’ 능력은 어떠한 메커니즘으로 작동하며, 그 능력과 자기편향성 발현 간의 인과 관계는 어떻게 심층적으로 설명될 수 있는가?
(2) 채용 외에 교육 분야의 AI 기반 과제 평가, 소셜 미디어 콘텐츠 조정, 학술 논문 검토 등 AI가 생성과 평가 양쪽에 관여하는 다른 고위험 의사결정 맥락에서도 유사한 자기편향성 패턴과 강도가 나타나는가?
(3) 다국어 또는 다문화 환경에서 비영어권 콘텐츠나 특정 문화적 배경의 콘텐츠에 대한 LLM의 자기편향성은 어떤 양상으로 나타나며, 이는 전 세계적인 AI 공정성 논의에 어떤 기술적, 윤리적, 사회적 함의를 던지는가?
출처
- Xu, J., Li, G., & Jiang, J. Y. (2025). AI Self-preferencing in Algorithmic Hiring: Empirical Evidence and Insights. Articles submitted to Manufacturing & Service Operations Management; manuscript no.