
AI, 하네스가 성능을 결정한다 — 모델을 감싼 운영체계
기술 현장에서는 늘 새로운 화두가 등장한다. 요즘 AI 이야기에서 ‘하네스(Harness)’는 단순히 안전띠나 가드레일을 뜻하지 않는다. 오히려 AI 모델이 실질적인 가치를 만들도록 둘러싸는 실행 구조 전체를 의미한다. 이 개념은 우리가 학교 현장에서 AI를 활용할 때 놓치기 쉬운 본질을 꿰뚫는다.
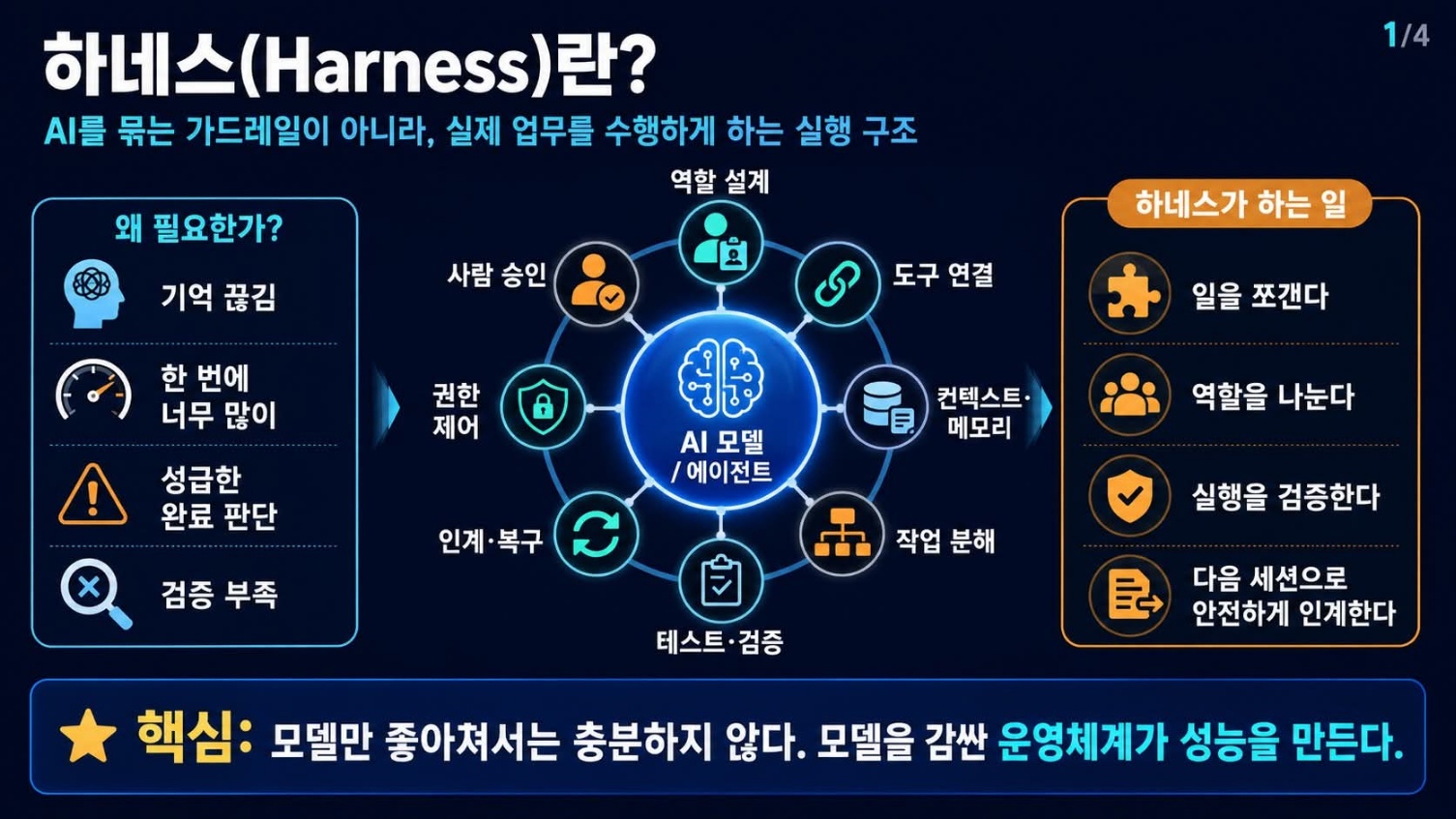
AI, ‘하네스’는 가드레일이 아니라 실행 운영체계다
많은 이가 AI의 발전, 특히 LLM의 성능 향상에만 집중한다. 그러나 경험상 모델 자체의 능력만으로는 기대한 성과를 얻기 어렵다. 마치 고성능 스포츠카에 낡은 내비게이션과 부실한 타이어를 장착하는 일과 다름없다. 하네스는 이 고성능 AI 모델이 복잡한 실제 환경에서 제대로 작동하도록 돕는 인프라이다.
초기에는 하네스를 AI의 오작동을 막는 ‘가드레일’ 정도로 여겼다. 그러나 현장에서 AI를 장기적으로, 반복적으로, 그리고 협업적으로 사용하면서 그 인식이 완전히 바뀌었다. 하네스는 단순한 통제 장치가 아니다. AI 모델이 실제 업무를 수행하기 위한 전체적인 ‘운영체계’로 기능한다. 모델이 아무리 뛰어나도, 이 운영체계가 부실하면 결국 기대 이하의 결과를 낳는다는 현실을 우리는 경험적으로 안다. 본질적으로, AI는 강력한 도구이지만, 그 도구를 어떻게 배치하고 활용하며 관리할지가 성패를 결정한다.
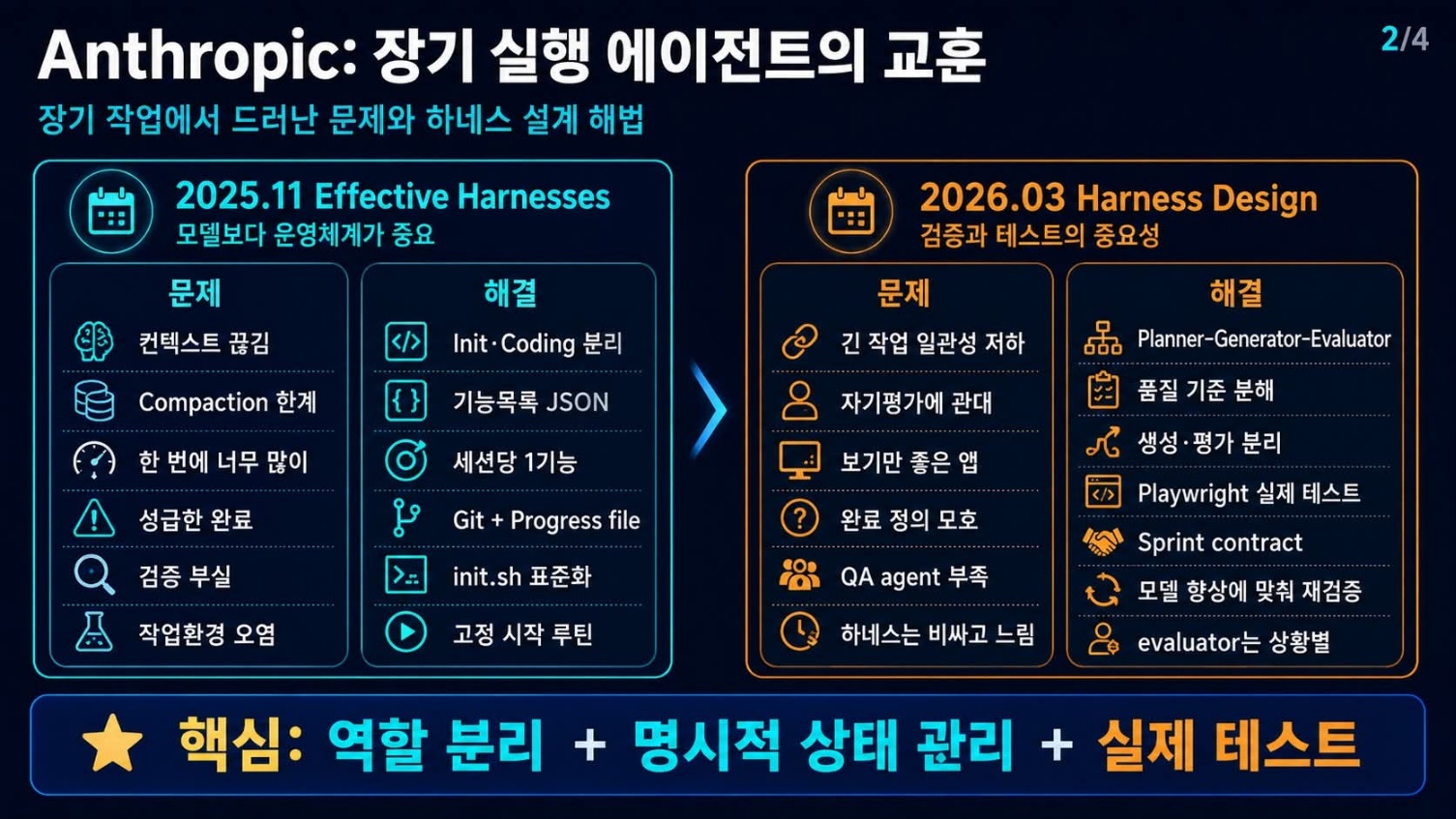
Anthropic의 통찰, 에이전트 장기 실행의 숨겨진 난관
Anthropic은 AI 에이전트의 장기 실행 과정에서 발생하는 문제와 그 해결책에 대한 깊이 있는 통찰을 제시했다. 2025년 11월에 발행한 ‘Effective Harnesses for Long-Running Agents’와 2026년 3월의 ‘Harness Design for Long-Running Apps’ 두 글은 AI 에이전트가 단기 작업을 넘어 복잡한 프로젝트를 수행할 때 겪는 난관을 구체적으로 보여준다.
Anthropic은 초기 AI 에이전트가 “기억 없는 새 작업자”처럼 컨텍스트를 잃거나, 한 번에 너무 많은 일을 하려다 길을 잃는 문제를 지적한다. 나아가 스스로 만든 결과물을 후하게 평가하고, ‘완료’의 정의조차 불명확하게 여기는 경향을 포착했다. 이는 우리가 학교에서 학생들에게 장기 프로젝트를 맡겼을 때 겪는 시행착오와 놀랍도록 유사하다. 학생이 진행 상황을 잊거나, 스스로의 결과물을 객관적으로 평가하지 못하는 상황과 다르지 않다.
그들이 제시한 해결책의 핵심은 역할 분리와 명확한 인계 구조였다. 예를 들어, 기획하는 에이전트와 코딩하는 에이전트를 분리하고, JSON 기능 목록으로 작업 단위를 명확히 하며, 각 세션에서는 한 기능만 처리하도록 제한한다. 또한 git과 progress file을 활용해 작업 인계 장치를 만들고, init.sh로 실행 방법을 표준화한다.
두 번째 글에서는 더욱 나아가 Planner-Generator-Evaluator라는 세 역할로 에이전트를 나누는 전략을 소개한다. 계획을 세우는 에이전트, 실제 결과물을 생성하는 에이전트, 그리고 그 결과물을 평가하는 에이전트를 분리하는 방식이다. Playwright MCP 같은 도구로 실제 사용 환경처럼 테스트하고, Sprint contract 개념을 도입하여 작업 완료 기준을 명확히 설정한다. 이 관점은 인공지능이 스스로 판단하는 영역을 엄격하게 제한하고, 인간의 설계적 지능을 확장하는 방향으로 하네스를 설계한다는 것을 명확히 보여준다.
Anthropic의 사례는 단순히 기술적 문제를 넘어선다. 우리는 AI 에이전트의 자율성을 무조건 확장하기보다, 인간의 관리 원칙을 적용하여 ‘좋은 AI 팀원’으로 길러내야 함을 배운다. 모델이 아무리 발전해도, 구조적 제어 없이는 그 잠재력을 온전히 발휘하기 어렵다. 이는 곧 교육 현장에서 AI 도구를 도입할 때, 그 도구의 기술적 성능뿐 아니라, 학생의 학습 과정에서 어떤 맥락에 어떻게 통합하고 평가할지에 대한 ‘설계’가 훨씬 중요함을 의미한다.
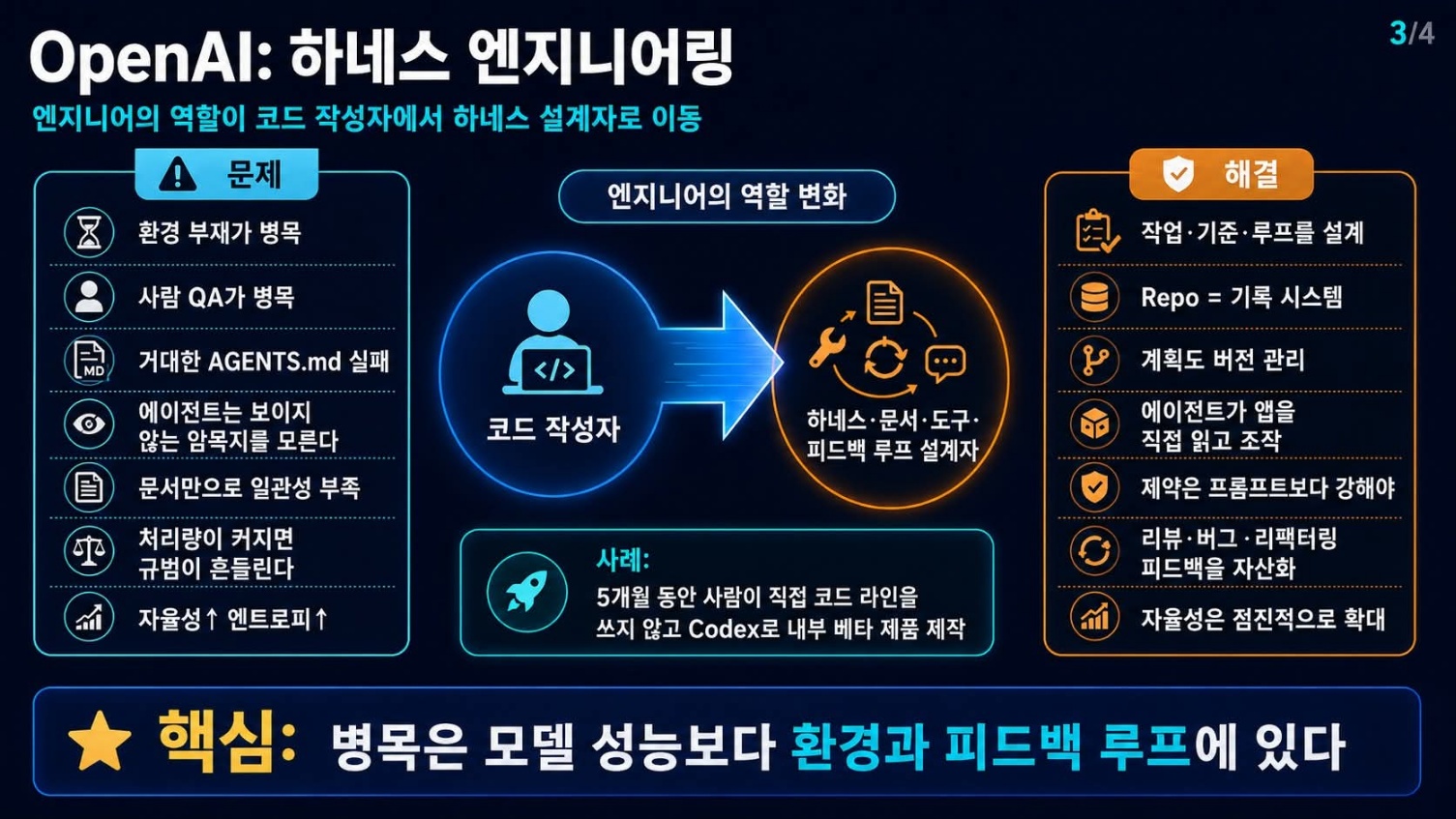
OpenAI의 전환, 엔지니어의 역할이 달라진다
OpenAI 역시 ‘하네스 엔지니어링(Harness Engineering)’이라는 개념으로 AI 시대의 엔지니어 역할 변화를 강조한다. 그들은 사람이 직접 코드 한 줄 쓰지 않고 OpenAI Codex로 내부 베타 제품을 5개월 동안 만들었다는 놀라운 경험을 공유한다. 이 과정에서 엔지니어의 역할이 ‘코드 작성자’에서 ‘하네스, 문서, 도구, 피드백 루프 설계자’로 변모했다고 설명한다.
이들의 경험은 우리에게 큰 질문을 던진다. 기술이 고도화될수록 인간의 역할은 무엇인가? OpenAI는 AI의 병목 현상이 에이전트의 성능보다 “환경 부재”에 있음을 지적한다. 사람의 QA와 주의력이 병목이 되고, 거대한 AGENTS.md 같은 문서만으로는 일관성을 유지하기 어렵다는 현실을 직시한다. 에이전트가 Google Docs, Slack 대화, 사람 머릿속의 암묵지 등 “볼 수 없는 것”을 모른다는 문제도 명확히 한다.
해결책은 엔지니어가 직접 코드를 쓰기보다, 작업을 정의하고, 기준을 만들며, 에이전트가 실행, 검증, 리뷰, 수정할 수 있는 루프를 설계하는 데 있다. 리포지터리를 에이전트의 “기록 시스템”으로 활용하고, 계획 또한 코드처럼 버전 관리해야 한다고 강조한다. 제약은 프롬프트보다 강해야 하며, 사람의 판단은 일회성 피드백으로 끝나지 않고 루프 안에 통합되어야 한다고 말한다. 에이전트의 자율성은 점진적으로 키워야 한다는 단언은 AI 도입의 속도 조절과 체계적인 접근의 중요성을 시사한다.
이 변화는 교육 현장의 교사 역할 전환과 맞닿아 있다. AI가 많은 지식 전달과 개인화된 학습 활동을 대체할 수 있게 될 때, 교사는 단순히 지식을 전달하는 역할을 넘어 학습 환경을 설계하고, 학생의 학습 과정을 관찰하며, 피드백 루프를 구축하는 역할로 진화한다. 이는 교사가 AI라는 강력한 도구를 효과적으로 다루기 위한 ‘하네스 엔지니어링’적 사고를 갖춰야 한다는 강력한 증거다.
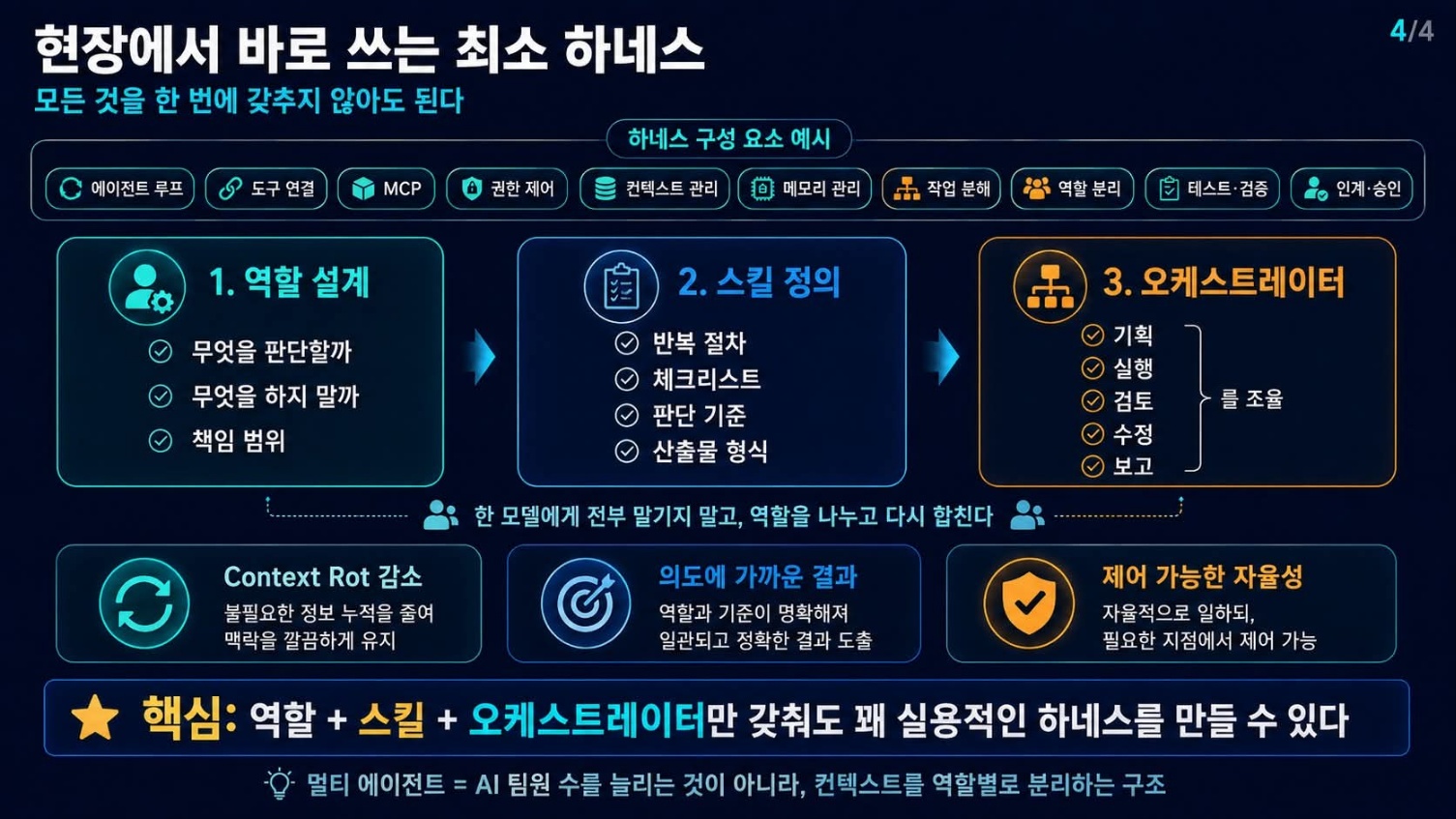
현장에서 바로 적용할 최소 하네스, 세 가지 핵심 요소
이처럼 거대한 변화 속에서 현장 교육자가 당장 적용할 수 있는 하네스 요소는 무엇일까? 카카오 FDE 황민호 님은 강의에서 현장에서 빠르게 적용 가능한 최소 단위의 하네스로 세 가지를 강조한다. 이 세 가지는 AI를 단순히 사용하는 것을 넘어, AI를 학습 설계의 파트너로 만드는 데 필수적이다.
- 에이전트의 역할 설계: “너는 무엇을 판단하고, 무엇을 하지 말아야 하는가”를 명확히 정한다. 이는 AI에게 모호한 지시를 내리지 않고, 구체적인 책임과 권한을 부여하는 과정이다. 예를 들어, “글쓰기 도우미”에게는 “초고 작성” 역할만 부여하고 “평가” 역할은 주지 않는 식이다. 이러한 역할 분리가 에이전트의 혼선(Context Rot)을 줄인다.
- 에이전트가 사용하는 스킬의 정의: 반복적으로 쓰는 절차, 체크리스트, 판단 기준, 산출물 형식을 스킬로 만들어둔다. 마치 교사가 학생들에게 과제 수행을 위한 루브릭이나 체크리스트를 제공하듯, AI에게도 명확한 ‘작업 매뉴얼’을 제공하는 일이다. 이는 AI의 일관성을 확보하고 예측 가능한 결과를 얻는 데 결정적인 역할을 한다.
- 여러 에이전트나 작업 단계를 조율하는 오케스트레이터: 기획, 실행, 검토, 수정, 보고를 한 모델에게 한꺼번에 맡기는 대신, 역할을 나누고 다시 합치는 구조다. 하나의 AI가 모든 것을 떠안으면 컨텍스트 혼란이 가중된다. 대신 ‘아이디어 발상 AI’ - ‘자료 검색 AI’ - ‘초고 작성 AI’ - ‘피드백 AI’ - ‘최종 정리 AI’ 등으로 역할을 분할하고, 이들을 유기적으로 연결하는 상위 오케스트레이터를 두는 방식이다.
이 세 가지 요소만 갖춰도 꽤 실용적인 수준의 하네스를 만들 수 있다. 이는 모델을 자연스럽게 제어하고, 우리가 요청한 의도와 방향에 더 가까운 결과를 얻도록 돕는다. AI의 성능은 그 자체로 결정되지 않는다. 우리가 AI를 어떤 목적에 어떻게 활용할지에 대한 명확한 설계, 곧 하네스 위에 세워진다. 교육 현장에서 AI를 단순 도구로만 볼 것인지, 아니면 학습 설계의 강력한 파트너로 만들 것인지는 이 하네스 설계 능력에 달려 있다.