
LLM 기반 멀티 에이전트 시스템은 협력 학습 스캐폴딩 테스트에 어떻게 활용될 수 있을까?
1. 연구의 목적
(1) 협력 학습 스캐폴딩에 대한 기존 연구는 시간과 자원이 많이 소요되어 교수 전략의 신속한 반복 및 최적화에 어려움이 있음. LLM 기반 멀티 에이전트 시스템은 복잡한 사회적 상호 작용을 시뮬레이션하고 교육 연구를 위한 새로운 패러다임을 제공하는 강력한 도구로 부상함.
(2) LLM 기반 멀티 에이전트 시뮬레이션 접근 방식을 통해 실제 교실 배치 전에 협력 학습 과정 및 교수 스캐폴드의 효과를 조사하는 것을 목표로 함. 특히 그룹 토론 시뮬레이션의 타당성과 이러한 시뮬레이션이 기존 학습 과학 이론과 일치하는지 여부를 검토함.
2. 연구의 방법
(1) MetaGPT 프레임워크와 GPT-4o를 사용하여 시뮬레이션 시스템을 구현함. 이 시스템은 교사 에이전트 1명과 학생 역할(리더, 서포터, 설명자, 반박자, 요약자) 5명으로 구성됨. “Deep Think before Speak”와 “Direct Speak” 두 가지 스캐폴딩 전략을 10개의 고전 중국 시 감상 과제에 걸쳐 비교함. 담화 품질과 행동에 대한 담론 분석을 통해 평가를 수행함.
- 조건 1: Deep Think before Speak 스캐폴딩
- 조건 2: Direct Speak 스캐폴딩
(2) 담화 품질 및 행동 양상에 대해 분석함. 두 명의 연구자가 담화 품질과 담화 행동을 코딩함. 코딩된 데이터의 20%에 대해 Kappa 값을 계산하여 코딩의 신뢰도를 검증함. GPT-4o를 활용하여 자동 코딩을 수행하고, 수동 코딩 결과와 비교하여 모델의 정확성을 검증함.
(3) 담화 품질은 유창성, 반복성, 모순, 관련성, 다양성의 5가지 차원으로 측정함. 담화 행동은 비효율적 학습 행동, 사회 관계적 행동, 협력적 분석 행동, 관점 구성 행동의 4가지 차원으로 측정함. 독립 표본 t-검정을 사용하여 두 스캐폴딩 조건 간의 차이를 분석하고, Benjamini-Hochberg 절차를 사용하여 p-값을 조정하여 다중 비교 문제를 해결함.
3. 주요 발견
(1) “Deep Think before Speak” 스캐폴드를 도입하면 에이전트의 담론 다양성과 상호 작용 깊이가 크게 향상되고 콘텐츠 반복성이 현저히 감소함. 행동 분석 결과, 해당 스캐폴드는 반영, 반박, 설명과 같은 더 복잡한 상호 작용 패턴을 장려하는 것으로 나타남.
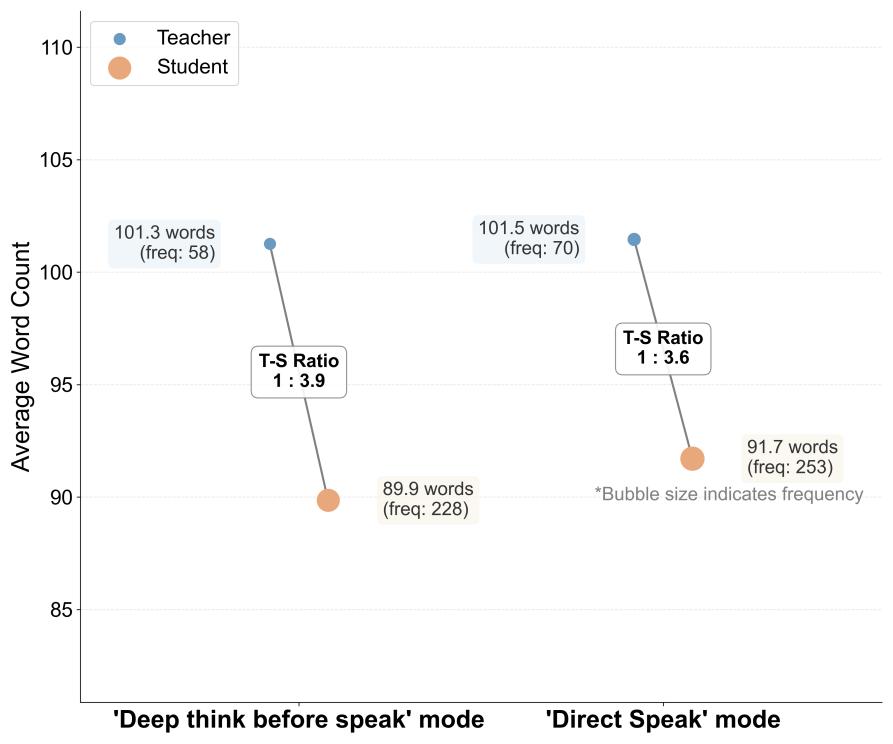
(2) 이러한 결과는 ICAP 프레임워크와 일치함. 스캐폴드는 에이전트가 단순한 “Active” 참여에서 “Constructive” 및 “Interactive” 지식 공동 구성으로 이동하도록 유도함.
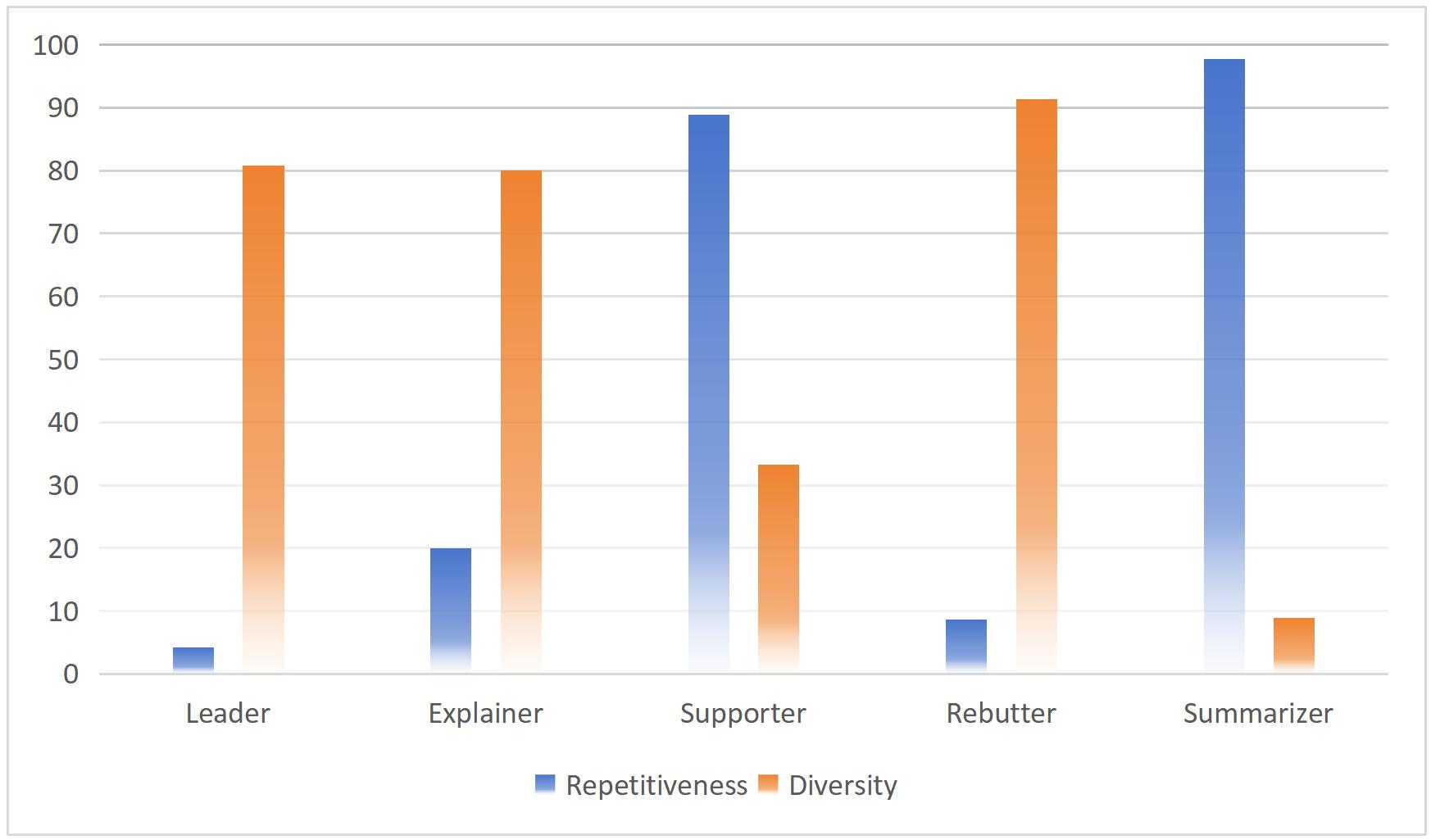
(3) “Deep Think before Speak” 모드는 학생 역할에 따라 담화 품질에 차이를 보임. 리더와 설명자는 높은 다양성을, 서포터는 높은 반복성을, 반박자는 높은 다양성과 낮은 반복성을, 요약자는 높은 반복성과 낮은 다양성을 나타냄.
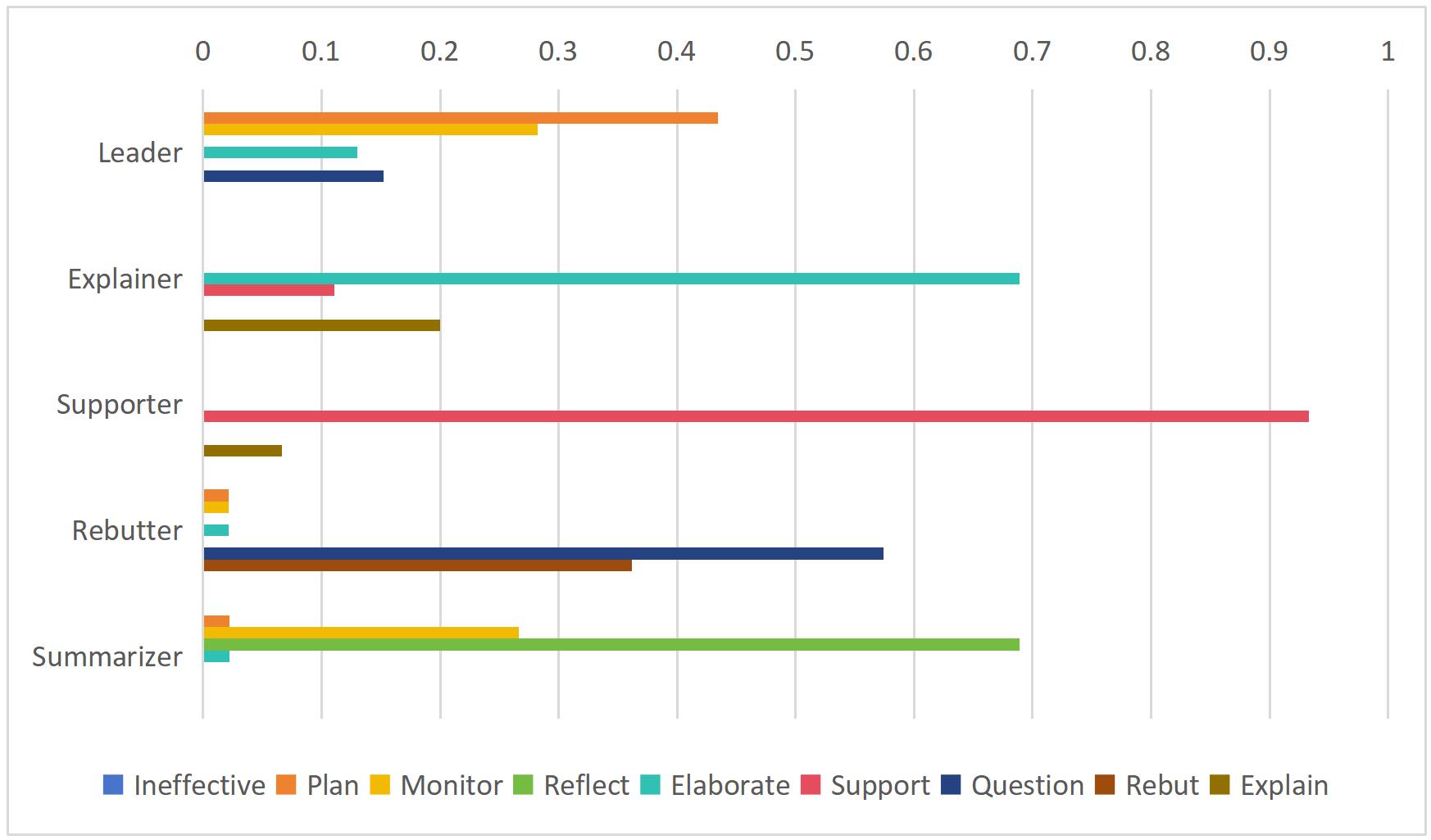
(4) “Deep Think before Speak” 모드는 “Direct Speak” 모드보다 학생 에이전트의 행동 전이 패턴을 다양하고 상호 연결되게 만듦.
4. 결론 및 시사점
(1) LLM 기반 멀티 에이전트 시스템을 사용하여 실제 협력 학습 역학을 시뮬레이션하는 타당성과 생태학적 타당성을 입증함. “Deep Think before Speak” 스캐폴딩은 담론의 질과 깊이를 향상시키는 데 효과적임.
(2) 교육 현장에서 LLM 기반 멀티 에이전트 시스템을 활용하여 협력 학습 스캐폴딩 전략을 설계하고 평가하는 데 도움을 줄 수 있음. AI 개발 측면에서 효과적인 협력 학습 시뮬레이션을 구축하기 위한 설계 원칙을 제공함.
5. 리뷰어의 ADD(+) One: 생각 더하기
(1) LLM을 활용하여 에이전트 기반 모델링을 수행하고, 이를 통해 사회적 상호작용을 시뮬레이션하려는 시도가 인상적임. 특히 교육 분야에서 협력 학습 환경을 구축하고 스캐폴딩 효과를 분석한 점이 중요함.
(2) 이 연구는 LLM 기반 에이전트가 인간 학습자의 인지적 프로세스를 모방하고, 사회적 상호작용을 통해 지식을 구성하는 과정을 시뮬레이션할 수 있음을 보여줌. 이는 사회적 구성주의 학습 이론과 연결되며, AI 에이전트가 학습 환경에서 중요한 역할을 수행할 수 있음을 시사함.
(3) 이 연구 결과는 고등 교육 환경, 특히 인문학 분야의 협력 학습 활동에 적용될 수 있음. 하지만 초등 교육이나 다른 교과에서는 학생들의 발달 단계나 학습 목표에 따라 스캐폴딩 전략을 조정해야 할 수 있음. 또한, 실제 학습 환경에서는 학생들의 동기 부여, 감정적 요인, 사회적 맥락 등 다양한 변수가 작용하므로, 시뮬레이션 결과가 그대로 적용되기 어려울 수 있음.
(4) LLM 기반 에이전트의 역할 분담을 더욱 세분화하고, 각 에이전트의 행동 패턴을 다양화하여 실제 학습 환경과 유사한 복잡성을 구현한다면 어떨까? 예를 들어, 특정 에이전트에게 긍정적인 피드백을 제공하는 역할, 다른 에이전트에게 도전적인 질문을 던지는 역할 등을 부여하여 더욱 역동적인 학습 환경을 조성할 수 있을 것임.
6. 추가 탐구 질문
(1) “Deep Think before Speak” 스캐폴딩이 LLM 기반 에이전트의 인지적 처리 과정에 미치는 구체적인 메커니즘은 무엇일까?
(2) 다양한 교과 내용이나 학습 목표에 따라 협력 학습 시뮬레이션의 설계 및 스캐폴딩 전략이 어떻게 달라져야 할까?
(3) LLM 기반 에이전트를 활용한 협력 학습 시뮬레이션의 기술적 한계(예: 계산 비용, 데이터 편향)와 윤리적 문제(예: 에이전트의 자율성, 책임)는 무엇이며, 어떻게 해결할 수 있을까?
<출처> - Wu, H., Zhang, L., & Lu, C. (2026). A Simulation-Based Method for Testing Collaborative Learning Scaffolds Using LLM-Based Multi-Agent Systems. *미발행*.