
EdTech 로그 데이터로 학생의 장기 학습 성과를 예측할 수 있을까?
1. 연구의 목적
(1) 교육 소프트웨어 사용은 늘었지만, 소프트웨어의 교육적 효과를 평가하는 일은 여전히 어려운 과제임. 특히 학년 말 주 평가와 같은 학생의 장기 학습 성과는 드물게 발생하여, 어떤 학생이 이러한 평가에서 어려움을 겪을지 조기에 알아내기 힘듦. 또한, 특정 교육 도구의 효과를 평가하는 데도 오랜 시간이 걸림. 기존 연구는 주로 학생의 전체 사용 기간 로그 데이터를 활용하거나, 짧은 시간 사용 후 즉각적인 단기 성과를 예측하는 데 집중했음.
(2) 이 연구는 학생들이 교육 기술을 처음 몇 시간 사용했을 때 생성된 로그 데이터를 통해 학년 말 외부 평가와 같은 장기 학습 성과를 얼마나 효과적으로 예측할 수 있는지 알아보고자 함. 이를 위해 세 가지 다른 교육 환경(우간다 리터러시 게임, 미국 수학 지능형 튜터링 시스템 2종)의 데이터를 활용하여, 단기 로그 데이터의 예측 유용성과 일반화 가능성을 탐색함. 나아가 학생 집단 전체뿐 아니라 성과에 따라 분류된 특정 학생 그룹에 대한 예측 품질도 분석함.
2. 연구의 방법
(1) 이 연구는 학생들의 교육 기술 사용 로그 데이터에서 추출한 특징(feature)을 기반으로 장기 외부 평가 성과를 예측하는 정량적 머신러닝 접근 방식을 사용함. 다양한 사용 기간의 로그 데이터를 활용하여 예측 모델을 훈련하고 평가함.
(2) 주요 분석 대상 및 비교 조건은 다음과 같음.
- 연구에 사용된 세 가지 교육 기술 데이터셋은 다음과 같음.
- CWTL-Reading (Can’t Wait to Learn): 우간다 학생 739명의 읽기 교육 게임 로그 데이터.
- MATHia: 미국 중학생 2644명의 수학 지능형 튜터링 시스템 로그 데이터.
- iReady: 미국 7학년 학생 428명의 수학 온라인 프로그램 로그 데이터.
- 예측 목표는 각 교육 기술 사용 후 몇 달 뒤에 치러진 학년 말 외부 평가 점수임.
- 예측 모델로는 선형 회귀(LR), 서포트 벡터 회귀(SVR), 랜덤 포레스트(RF) 세 가지를 사용했으며, 단순 평균 예측을 베이스라인으로 설정함.
- 예측 성능은 다음 세 가지 조건에서 비교함.
- 로그 데이터 사용 기간: 1시간, 2시간, 3시간, 4시간, 5시간, 12시간, 전체 사용 기간(H).
- 예측 특징: 로그 데이터에서 추출한 특징만 사용한 경우와, 사전 평가 점수를 추가로 포함한 경우를 비교함.
- 학생 그룹: 전체 학생 집단, 성과에 따라 5개 분위수(Q1~Q5)로 나눈 그룹, 그리고 ‘통과’와 ‘실패’ 이진 분류 그룹에 대한 예측 품질을 평가함.
- 모델 성능 지표로는 RMSE (Root Mean Squared Error)와 R2 (결정 계수)를 사용했고, 그룹별 예측 품질은 혼동 행렬(Confusion Matrix)로 시각화함.
3. 주요 발견
(1) 초기 단기 로그 데이터의 장기 성과 예측 가능성 이 연구는 세 가지 교육 기술(CWTL-Reading, MATHia, iReady) 모두에서 초기 몇 시간(2~5시간)의 짧은 로그 데이터만으로도 학생의 몇 달 뒤 학년 말 외부 평가 성과를 유용하게 예측할 수 있음을 발견했음. 이는 전체 사용 기간의 로그 데이터를 사용했을 때와 거의 동등하거나 때로는 더 나은 예측 성능을 보임.
- CWTL-Reading 데이터셋의 경우, 랜덤 포레스트 모델이 5시간 사용 로그에서 가장 낮은 RMSE(0.13)와 가장 높은 R2(0.34)를 기록함.
- MATHia 데이터셋에서는 2시간 사용 로그로도 전체 기간 로그 데이터보다 더 나은 성능을 보임.
- iReady 데이터셋에서는 3시간 사용 로그에서 가장 좋은 초기 예측 성능을 얻었음.
흥미로운 점은 사용 시간이 길어진다고 해서 항상 예측 성능이 비례하여 좋아지지는 않는다는 것임. CWTL-Reading과 MATHia 모두에서 가장 긴 사용 기간(전체 로그 데이터)에서는 오히려 성능이 소폭 감소하는 경향을 보임. 이는 추가적인 데이터가 예측에 불필요한 노이즈를 포함할 수 있음을 시사함.
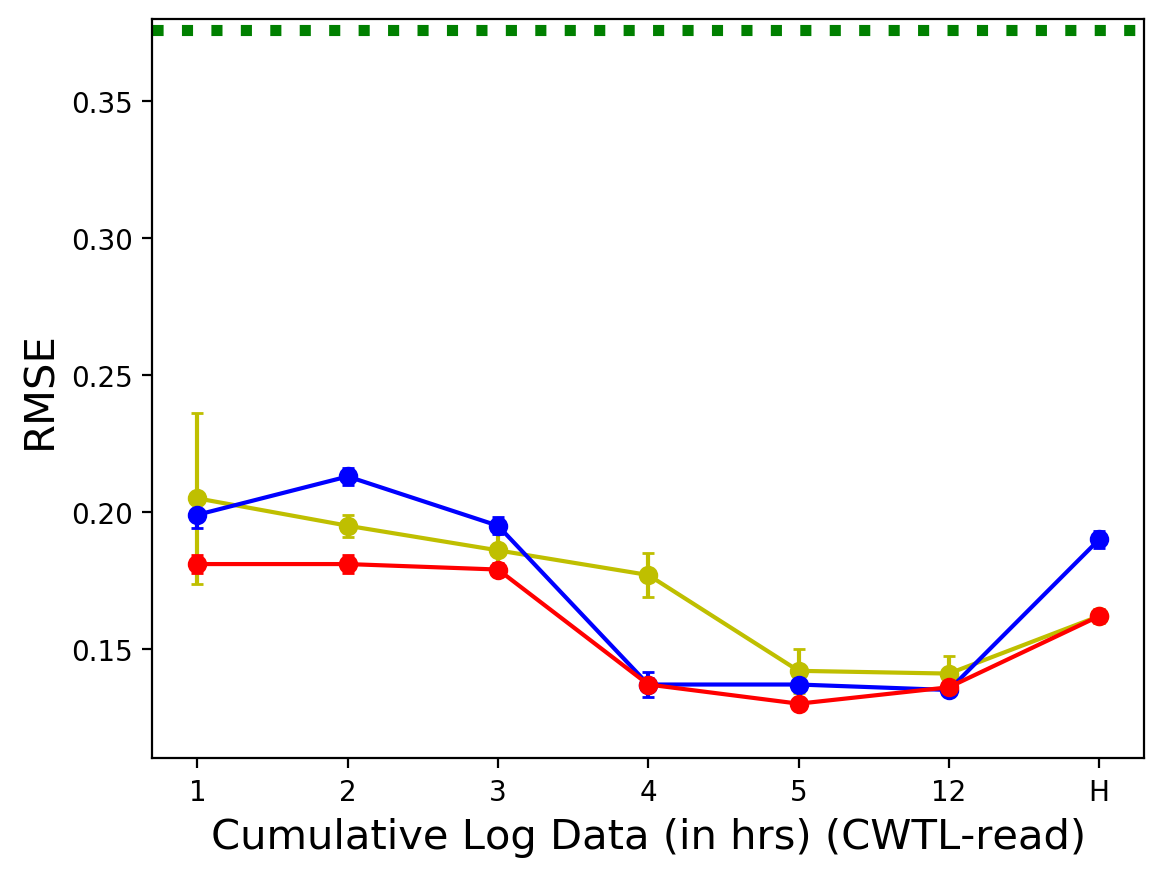
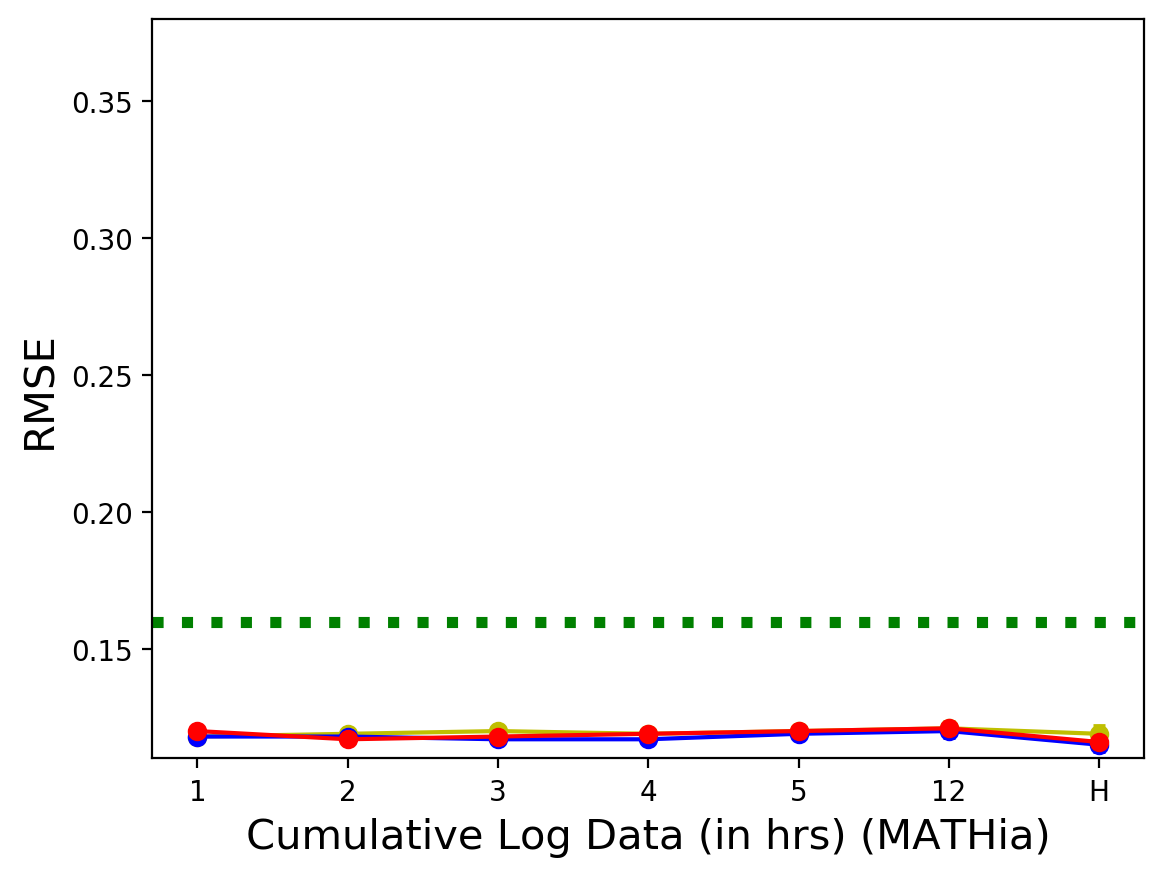
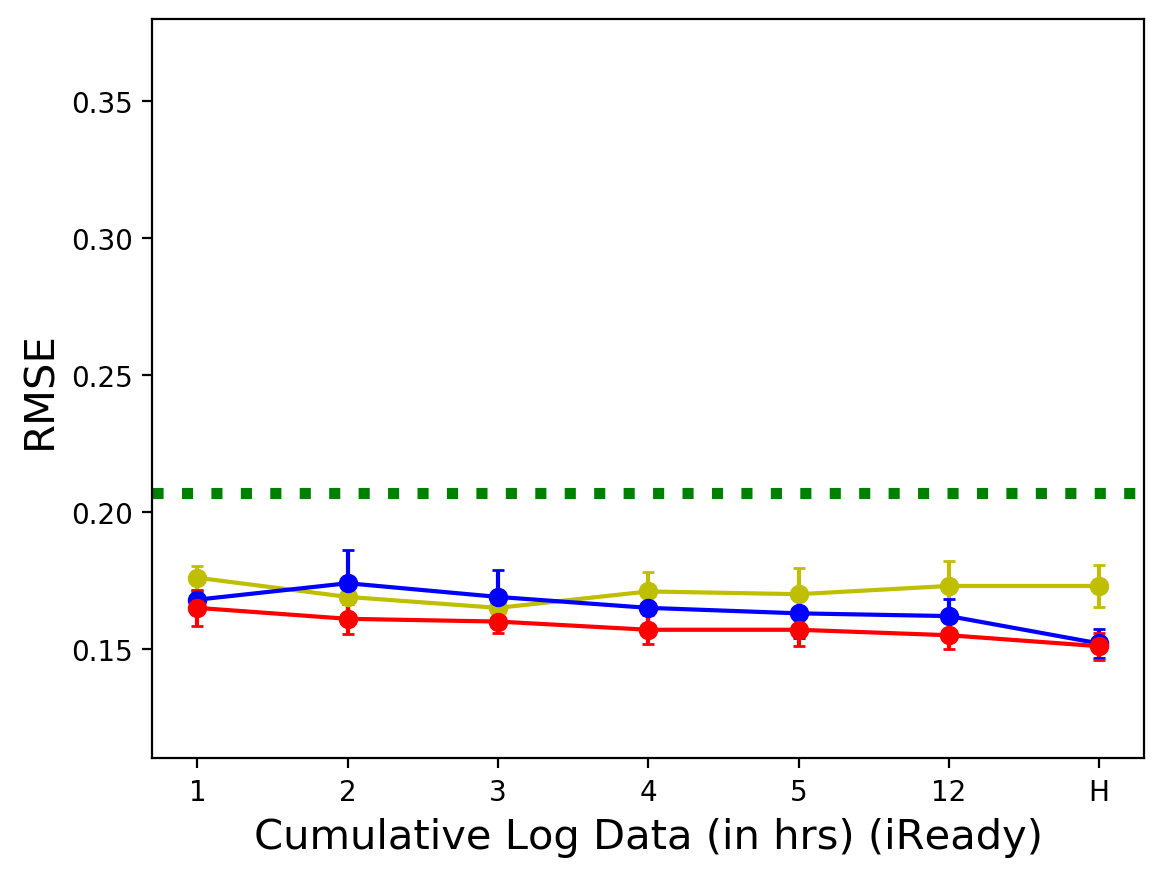 세 데이터셋 모두에서 누적 사용 시간이 늘어남에 따라 RMSE가 감소하거나 일정 수준을 유지하는 경향을 보이다가, 특정 시점 이후에는 소폭 증가하거나 변화가 미미한 것을 확인할 수 있음.
세 데이터셋 모두에서 누적 사용 시간이 늘어남에 따라 RMSE가 감소하거나 일정 수준을 유지하는 경향을 보이다가, 특정 시점 이후에는 소폭 증가하거나 변화가 미미한 것을 확인할 수 있음.
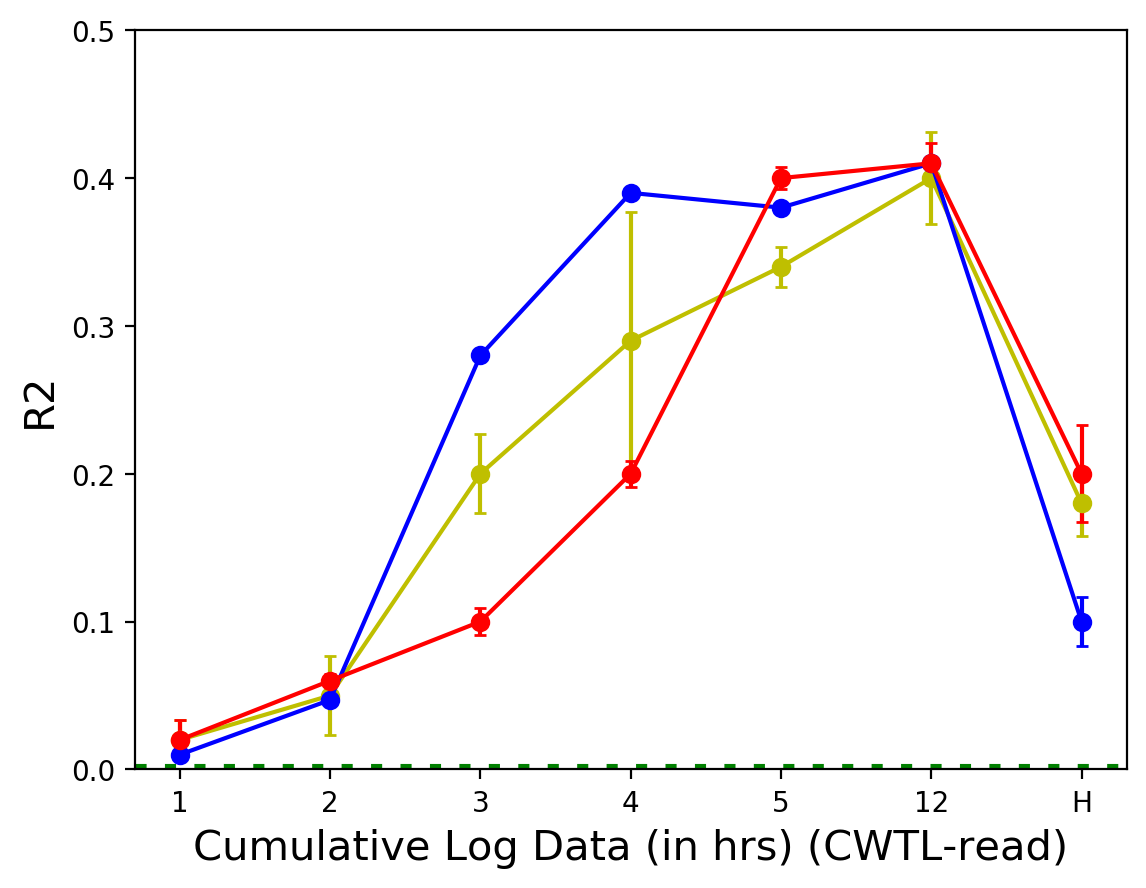
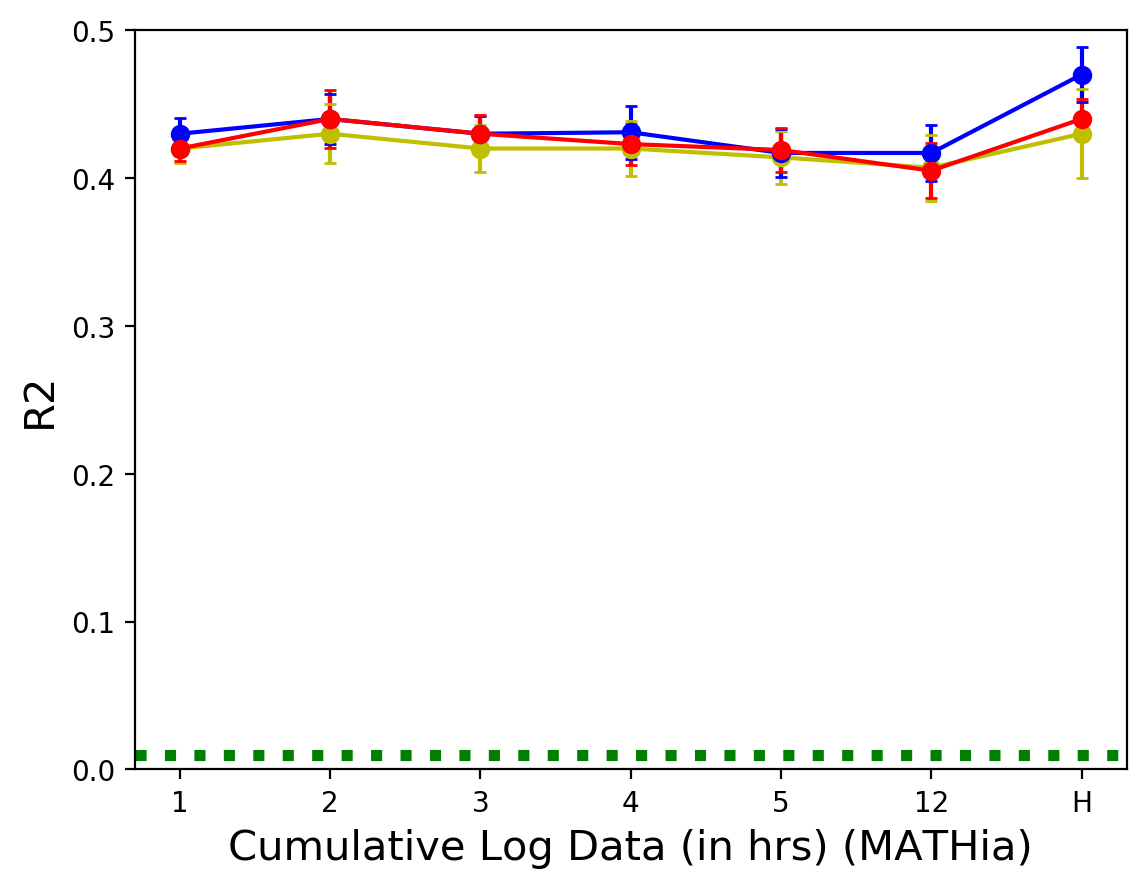
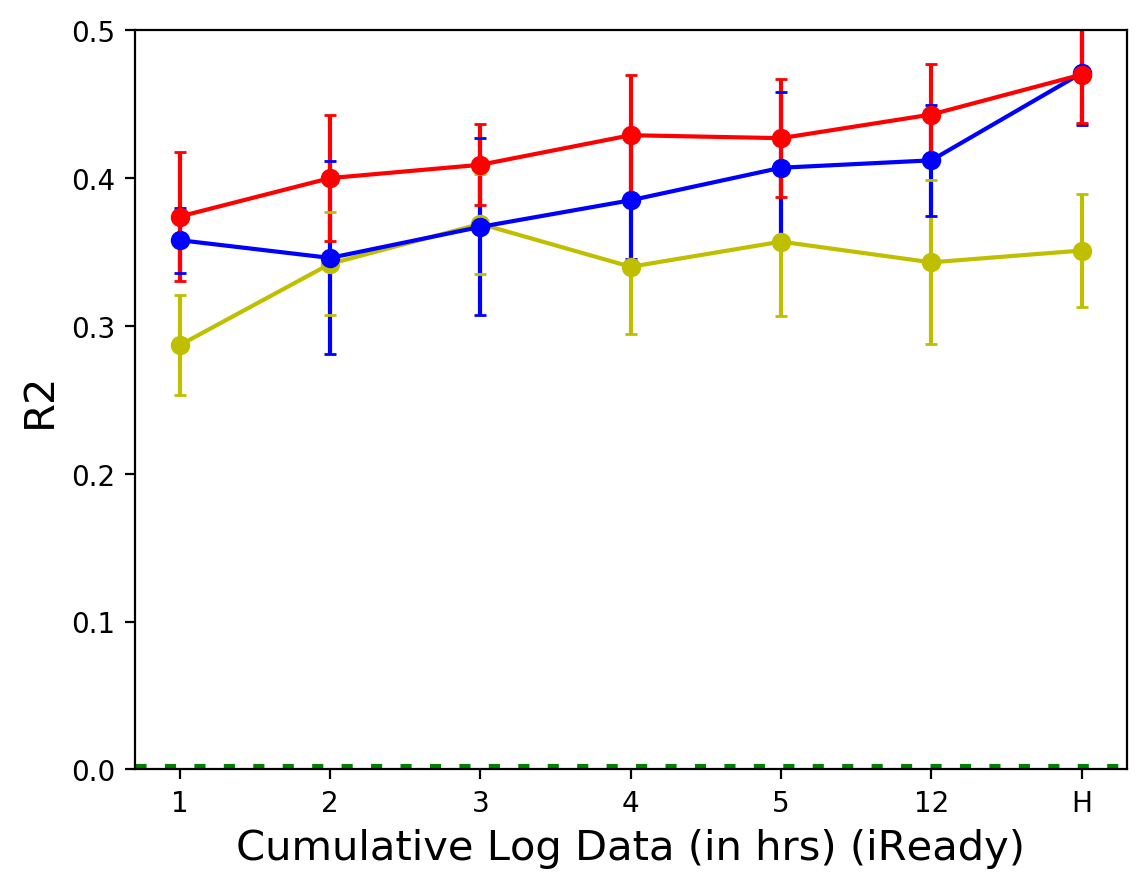 R2 값 역시 누적 사용 시간에 따른 변화 양상이 RMSE와 유사하게 나타나, 짧은 사용 시간 내에 대부분의 예측력이 확보됨을 보여줌.
R2 값 역시 누적 사용 시간에 따른 변화 양상이 RMSE와 유사하게 나타나, 짧은 사용 시간 내에 대부분의 예측력이 확보됨을 보여줌.
(2) 머신러닝 알고리즘의 영향은 미미함 선형 회귀, 서포트 벡터 회귀, 랜덤 포레스트 등 세 가지 머신러닝 알고리즘 간의 예측 성능 차이는 상대적으로 작았음. 랜덤 포레스트가 CWTL-Reading과 iReady 데이터셋에서 약간 더 나은 성능을 보였지만, 전반적으로 큰 차이는 없었음. 이는 다양한 표준 머신러닝 모델이 짧은 로그 데이터 예측에 유용하게 사용될 수 있음을 의미함.
(3) 교육 환경 전반에 걸쳐 중요한 로그 데이터 특징 여러 교육 환경과 사용 기간에 걸쳐 일관되게 중요한 예측 변수로 다음 두 가지 특징이 나타남.
- 문제 성공률 (Percentage of Success Problems): 학생이 문제를 성공적으로 해결한 비율을 뜻함. 예를 들어, 10문제 중 8문제를 맞혔다면 성공률은 80%임.
- 문제당 평균 시도 횟수 (Average Attempts per Problem): 한 문제를 해결하기 위해 평균적으로 몇 번 시도했는지를 뜻함. 예를 들어, 한 문제에 3번 시도하고 다음 문제에 2번 시도했다면 평균 시도 횟수는 2.5회임. 특히, 문제 성공률은 여러 데이터셋에서 가장 중요한 특징으로 자주 선정됨. 단일 특징만 사용한 예측 모델도 베이스라인보다는 성능이 좋았지만, 전체 로그 데이터 특징 세트를 사용한 모델이 더 뛰어난 예측력을 보였음. 이는 개별 특징도 중요하지만, 다양한 특징을 조합했을 때 더 복잡한 학습 패턴을 포착하여 예측력을 높일 수 있음을 나타냄.
(4) 성과 기반 학생 그룹별 예측 품질 모델은 학생들을 성과에 따라 5개 분위수(Q1~Q5)로 나눴을 때, 가장 낮은 성과 그룹(Q1)과 가장 높은 성과 그룹(Q5)에 대한 예측 정밀도가 높았음. 즉, 모델이 어떤 학생이 매우 어려움을 겪을지 또는 매우 잘할지를 예측했을 때, 그 예측이 맞을 가능성이 높다는 의미임. 그러나 중간 성과 그룹(Q3)에 대한 예측은 과대 또는 과소 추정되는 경향이 있었음. MATHia 데이터셋에서 ‘통과’ 또는 ‘실패’ 그룹을 예측했을 때, ‘실패’할 학생들을 놓치는 경우가 많았지만(낮은 재현율), ‘실패’를 예측한 경우 74%는 실제로 ‘실패’하는 높은 정밀도를 보였음. 이는 모델이 극단적인 성과를 보이는 학생들을 식별하여 조기에 맞춤형 지원이나 심화 학습을 제공하는 데 잠재적인 가치가 있음을 시사함.
(5) 사전 평가 점수의 영향 사전 평가 점수(pre-test)는 학생의 장기 성과를 예측하는 데 매우 강력한 단독 지표로 작용함. 즉, 다른 정보 없이 사전 평가 점수만으로도 충분히 유용한 예측이 가능함을 뜻함. 로그 데이터 특징만 사용하는 것보다 사전 평가 점수만 사용하는 것이 더 나은 성능을 보이기도 했음. 또한, 사전 평가 점수를 로그 데이터 특징과 결합했을 때 예측 성능이 더욱 향상되는 경우가 많았음. 특히 R2 값이 크게 높아져, 모델의 설명력이 더 커졌음을 보여줌. 이는 사전 평가 점수를 사용할 수 있다면 예측 모델에 포함하는 것이 매우 유리하다는 것을 의미함.
4. 결론 및 시사점
(1) 이 연구는 학생들이 교육 기술을 2~5시간만 사용한 짧은 로그 데이터만으로도 몇 달 후의 장기적인 외부 학습 성과(학년 말 시험 등)를 유용하게 예측할 수 있음을 입증함. 이러한 단기 데이터 기반 예측은 전체 사용 기간의 로그 데이터를 사용했을 때와 유사하거나 때로는 더 나은 성능을 보였음. 특히 문제 성공률과 문제당 평균 시도 횟수가 여러 교육 환경에서 중요하고 일반적인 예측 특징으로 나타났음.
(2) 이 연구는 교육 현장에 다음과 같은 중요한 시사점을 제공함. 학생들이 교육 기술을 사용한 초기 단계에서 얻은 데이터를 활용하여 누가 추가적인 지원이 필요하거나, 반대로 더 큰 도전을 통해 잠재력을 발휘할 수 있는지를 조기에 식별할 수 있음. 교사들은 이러한 예측 정보를 바탕으로 학생의 학습 진행 상황을 더 잘 이해하고, 개별 학생이나 학급 전체를 위한 맞춤형 교육 전략과 개입을 더 적시에 수립할 수 있음.
(3) 또한, 사전 평가 점수는 장기 성과 예측에 매우 강력한 지표이지만, 항상 사용할 수 있거나 학습 시간을 침해하지 않을 수 없는 한계가 있음. 이 연구는 사전 평가 점수를 사용할 수 없는 상황에서도 짧은 로그 데이터가 효과적인 대안이 될 수 있음을 보여줌. 이는 교육 현장에서 사전 평가에 소요되는 시간과 자원을 절약하면서도 학생의 장기 성과에 대한 중요한 정보를 얻을 수 있는 가능성을 열어줌.
5. 리뷰어의 ADD(+) One: 생각 더하기
(1) 이 논문에서 가장 주목할 지점은 학생의 ‘짧은’ 교육 기술 사용 로그 데이터만으로도 ‘장기’ 학습 성과를 예측하는 데 유의미한 정확도를 달성했다는 점임. 기존 연구들은 주로 전체 사용 기간의 데이터를 사용하거나, 짧은 사용 후 즉각적인 단기 성과 예측에 머물렀음. 이 연구는 이러한 한계를 넘어, 데이터 수집의 효율성과 예측의 시의성을 극대화했음. 이는 교육 개입의 타이밍을 현저히 앞당겨 학생들에게 더 빠르고 효과적인 지원을 제공할 수 있다는 점에서 교육 현장의 실용적 가치가 매우 높음. ‘대리 지표(surrogate endpoint)’라는 개념을 교육 맥락에 성공적으로 적용하여, 기존의 오랜 평가 과정을 단축시키면서도 신뢰성 있는 정보를 얻을 수 있음을 보여준 것이 핵심적인 기여임.
(2) 이 연구의 결과는 교육 분야를 넘어 더 넓은 의미를 가짐.
- 교육 정책 수립: 초기 학습 데이터를 통한 조기 예측은 교육 정책 입안자들이 자원 배분, 교육 프로그램 설계, 교육 개입의 효과성 평가 등에 대한 의사결정을 더 신속하고 유연하게 할 수 있도록 지원함. 장기적인 효과를 예측하여 정책의 방향을 조기에 조정할 수 있게 되는 것임.
- 인간-컴퓨터 상호작용 (HCI) 및 교육 AI 설계: 교육 AI 시스템이 학생과의 초기 상호작용 데이터를 바탕으로 학습자의 인지 상태, 동기 수준, 학습 스타일 등을 예측하고, 이를 기반으로 최적화된 학습 경로, 맞춤형 피드백, 적절한 난이도의 과제를 제공하는 개인화된 학습 경험을 고도화할 수 있음. 사용자 경험 설계자들은 초기 데이터의 중요성을 인지하고, AI 시스템이 학습자의 미묘한 행동 패턴을 포착하고 해석하는 능력에 더 집중해야 할 것임.
(3) 이 연구를 발전시킬 구체적인 아이디어는 다음과 같음.
- 예측의 설명 가능성(Explainability)을 강화한 대시보드 개발: 현재 모델은 예측을 하지만, 교사가 ‘왜’ 특정 학생이 어려움을 겪을 것으로 예측되는지 이해하기 어려움. 이를 해결하기 위해 SHAP(SHapley Additive exPlanations) 값이나 LIME(Local Interpretable Model-agnostic Explanations)과 같은 설명 가능한 AI(XAI) 기법을 적용하여, 어떤 로그 특징(예: 낮은 문제 성공률, 높은 시도 횟수)이 특정 학생의 성과 예측에 가장 큰 영향을 미쳤는지 직관적으로 시각화하는 대시보드를 개발할 수 있음. 이 대시보드는 교사가 학생에게 더 의미 있는 피드백을 제공하고, AI 예측에 대한 신뢰도를 높이는 데 결정적으로 기여할 것임.
- 동적이고 적응적인 예측 및 개입 시스템 구축: 이 연구는 고정된 짧은 시간(예: 2~5시간) 데이터를 사용했지만, 실제 교육 환경에서는 학생의 학습 진행에 따라 예측 모델이 실시간으로 업데이트되어야 함. 학생의 학습 활동이 특정 패턴을 보이거나, 예측된 위험도가 설정된 임계치를 넘어서는 순간 교사에게 자동으로 알림을 보내고, 맞춤형 교육 개입 방안을 제안하는 시스템을 개발할 수 있음. 예를 들어, AI가 ‘이 학생은 문제 성공률이 급격히 낮아지고 있으니, 심화 피드백이나 개인 지도 선생님과의 상담이 필요합니다’와 같은 구체적인 제안을 하는 것임. 이는 교사가 더 적시에, 더 효과적으로 개입할 수 있는 기반을 제공할 것임.
6. 추가 탐구 질문
(1) 이 연구는 예측 모델이 중간 성과 그룹 학생들의 성과를 정확하게 식별하는 데 어려움을 겪는다고 언급함. 이 한계를 극복하기 위해 초기 로그 데이터에서 어떤 종류의 미세한 학습 행동 패턴(예: 특정 오답 유형, 반복적인 특정 도구 사용, 비정상적인 활동 시간대)을 추가로 포착해야 하며, 이를 통해 모델의 예측 정밀도를 어떻게 향상시킬 수 있을까?
(2) 본 연구는 주로 K-12 교육 환경에 초점을 맞춤. 학생의 자율성, 동기 부여 수준, 학습 목표 등이 다른 고등 교육, 성인 직업 훈련 또는 비정규 학습 환경에서도 초기 로그 데이터가 장기 성과를 예측하는 데 유사한 유효성을 가질까? 만약 차이가 있다면, 그 이유는 무엇이며 어떤 다른 특징이 더 중요해질까?
(3) 학생의 초기 학습 데이터를 기반으로 장기 성과를 예측하고 이를 교육적 개입에 활용할 때, 예측의 오차나 ‘너는 실패할 거야’와 같은 낙인 효과(labeling effect)로 인해 발생할 수 있는 잠재적인 윤리적 문제는 무엇일까? 이러한 윤리적 문제를 최소화하고 학생의 학습 기회와 자율성을 보호하기 위한 AI 시스템 설계 및 교육 정책적 가이드라인은 어떻게 마련되어야 할까?
<출처> - Gao, G., Leon, A., Jetten, A., Turner, J., Almoubayyed, H., Fancsali, S., & Brunskill, E. (2024). Predicting Long-Term Student Outcomes from Short-Term EdTech Log Data. *arXiv preprint arXiv:2401.15737*.