
AI 에이전트는 장기 소프트웨어 작업을 얼마나 수행하는가?
1. 연구의 목적
(1) 현재 AI 벤치마크는 실제 세상에서의 AI 능력치를 명확히 보여주지 못함. 기존 벤치마크는 인위적인 작업 위주임. 모델 역량이 급증함에도, 다른 벤치마크 간의 성능 비교가 어려워 AI 발전 현황을 직관적으로 이해하기 어려운 한계가 있음.
(2) 인간의 작업 소요 시간과 비교해 AI 모델의 실제 역량을 정량적으로 평가하는 새로운 지표인 50% 작업 완료 시간 지평 (50%-task-completion time horizon)을 제안하고 그 추세를 분석함. 이 지표로 AI 시스템이 인간의 복잡한 소프트웨어 작업을 자동화하는 능력을 예측함.
2. 연구의 방법
(1) 시간 지평 (Time Horizon)이라는 새로운 평가 방법론을 제시함. AI 모델이 특정 성공 확률로 완료할 수 있는 작업의 길이를 측정하는 방식임. 이는 인간이 해당 작업을 완료하는 데 걸리는 시간과 비교하는 것임. 특히 50% 성공률을 기준으로 함. Item Response Theory (IRT)에서 영감을 받은 로지스틱 회귀 모델을 사용함.
(2) 170개의 소프트웨어 및 기계 학습 연구 관련 작업으로 구성된 데이터셋을 활용함. 이 데이터셋은 기존의 HCAST (97개, 1분~30시간 소요), RE-Bench (7개, 모두 8시간 소요) 작업에 더해, SWAA (Software Atomic Actions)라는 66개의 짧은 신규 작업(1초~30초 소요)을 포함함. 도메인 전문성을 지닌 인간 기준선 (human baseliner) 800명 이상이 2,529시간을 들여 이 작업들을 수행하며 소요 시간을 측정함. 2019년부터 2025년까지 출시된 12개 최신 AI 모델의 성능을 평가하고, 이를 인간 기준선과 비교 분석함.
3. 주요 발견
이 연구는 AI 에이전트의 작업 완료 능력, 특히 50% 작업 완료 시간 지평이 지난 6년간 기하급수적으로 성장했음을 보여줌.
(1) AI 에이전트의 50% 작업 완료 시간 지평: AI 모델이 50%의 성공률로 완료할 수 있는 작업의 길이가 2019년부터 2025년까지 약 7개월마다 두 배로 증가했음. 특히 2024년 이후에는 이러한 추세가 더욱 가속화되었을 가능성이 높음. 초기 GPT-2의 시간 지평이 2초에 불과했지만, 최신 o3 모델은 110분의 시간 지평을 보여줌. 이는 인간에게 4시간 이상 걸리는 여러 작업을 성공적으로 완료함을 의미함.
(2) 성장 동력: 신뢰성, 오류 적응, 논리적 추론, 도구 활용 능력 향상: AI 모델의 시간 지평 증가는 주로 네 가지 핵심 능력의 개선에 기인함.
- 신뢰성: 불확실한 환경에서도 작업을 일관성 있게 완료하는 능력 향상.
- 오류 적응: 실패한 행동을 반복하지 않고, 스스로 실수를 인식하여 수정하는 자가 교정 능력 증대.
- 논리적 추론: 복잡한 문제를 해결하기 위한 논리적 사고 및 코드 생성 능력 향상.
- 도구 활용: 외부 도구를 효과적으로 사용하여 작업을 수행하는 능력 발전.
다음은 GPT-4 1106과 o1 모델의 실패 유형을 비교한 표임. o1이 GPT-4에 비해 ‘실패한 행동 반복’이 현저히 줄었음을 보여줌.
| 실패 유형 | GPT-4 1106 (31회 실패) | o1 (32회 실패) |
|---|---|---|
| 불충분한 계획/도구 선택 | 4 | 6 |
| 부정확한 논리적 추론/계산 | 6 | 7 |
| 조기 작업 포기 | 8 | 16 |
| 실패한 행동 반복 | 12 | 2 |
| 기타 | 1 | 1 |
| 총계 | 31 | 32 |
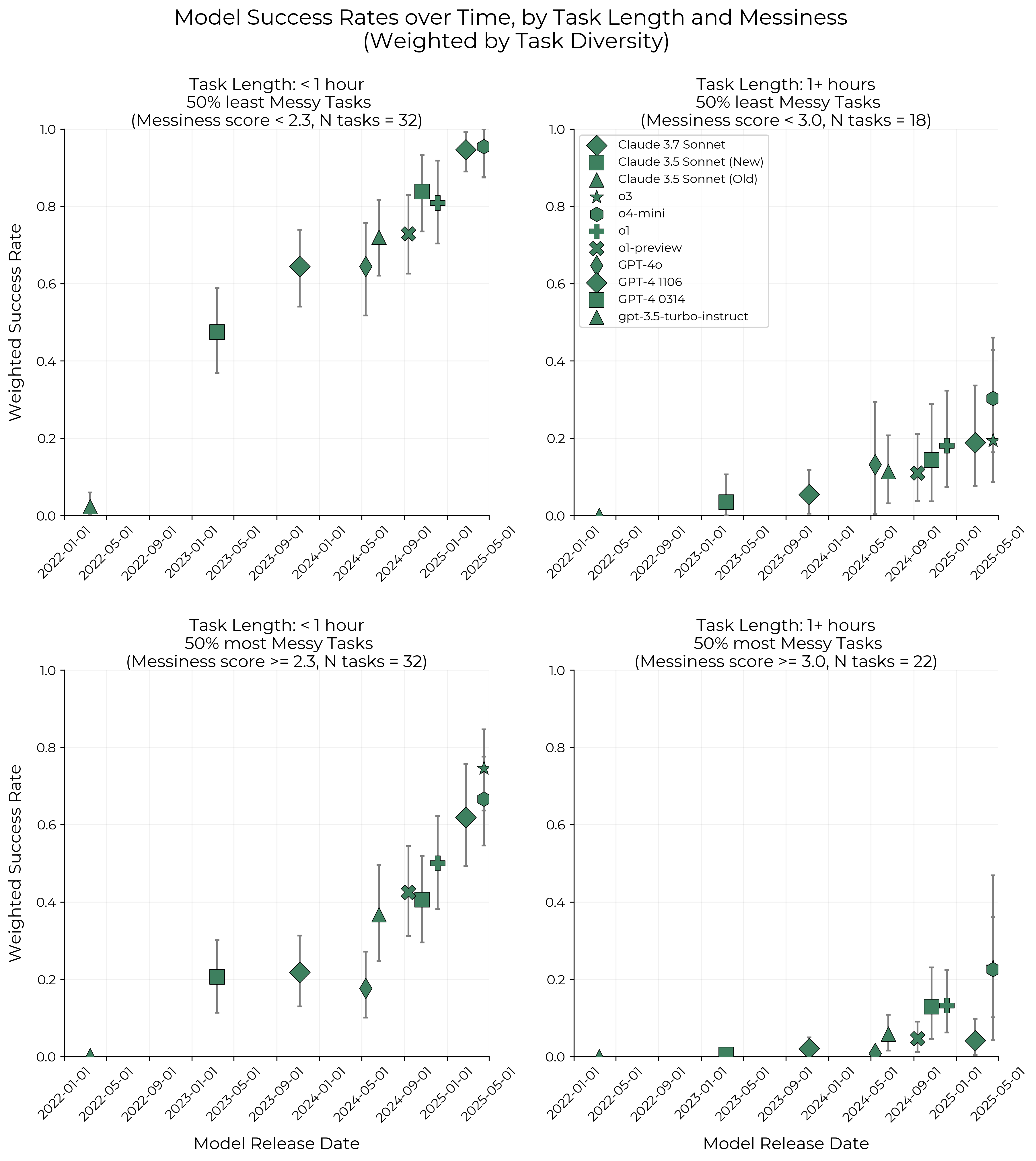
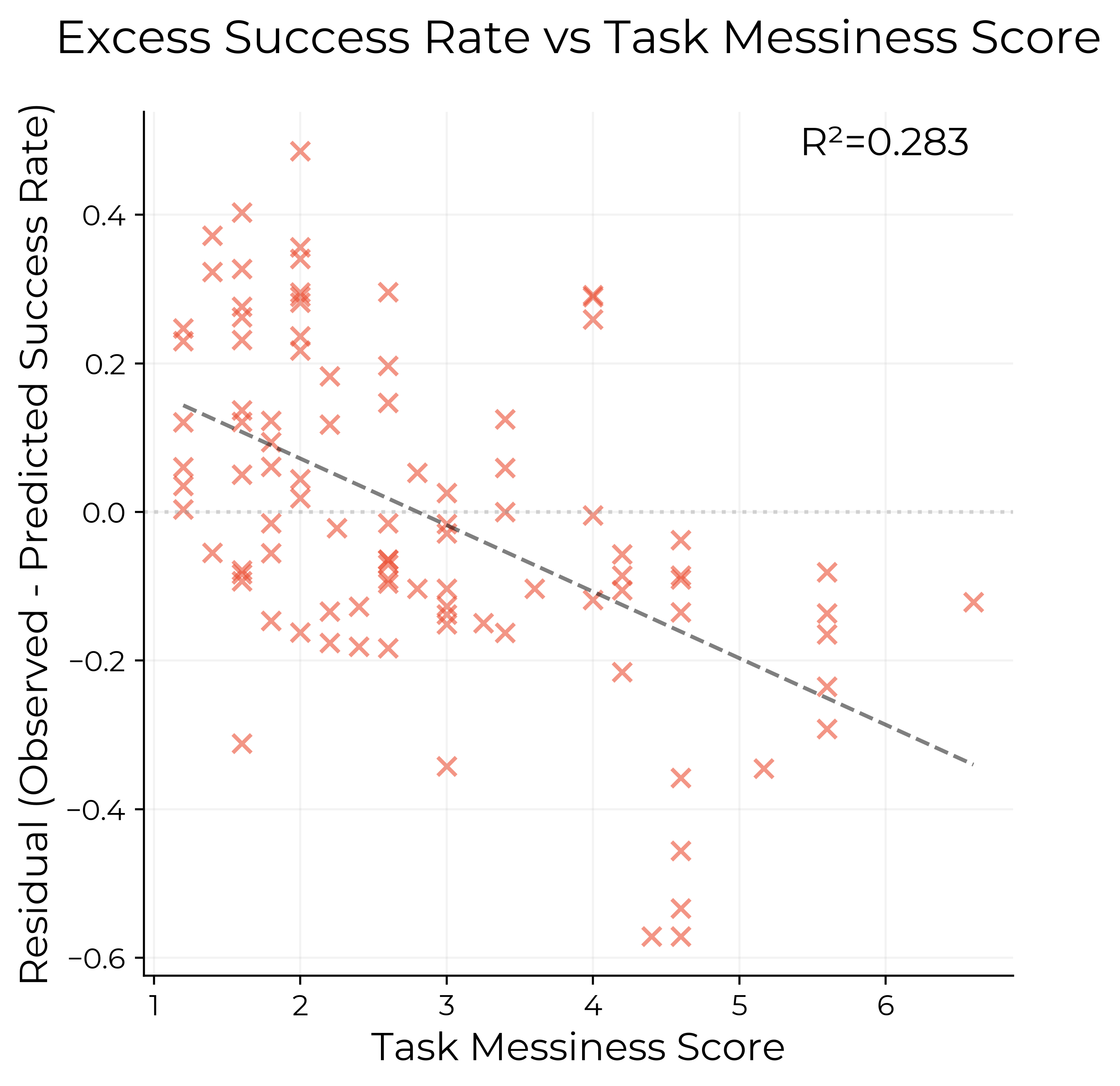
(3) ‘정돈되지 않은’ (Messy) 작업에서의 한계: AI 에이전트는 피드백 루프가 불분명하거나, 스스로 관련 정보를 능동적으로 찾아야 하는 ‘정돈되지 않은’ 환경에서는 여전히 어려움을 겪음. 예를 들어, 단위 테스트나 자동화된 확인 스크립트처럼 명확한 피드백이 없는 상황에서는 해결책의 정확성을 판단하기 힘들어 함. 이는 AI의 절대적인 성능이 ‘정돈되지 않은’ 작업에서 낮음을 의미하나, 이러한 유형의 작업에서도 시간에 따른 성능 향상 추세는 ‘덜 정돈된’ 작업과 유사하게 나타남 (Figure 12 참조).
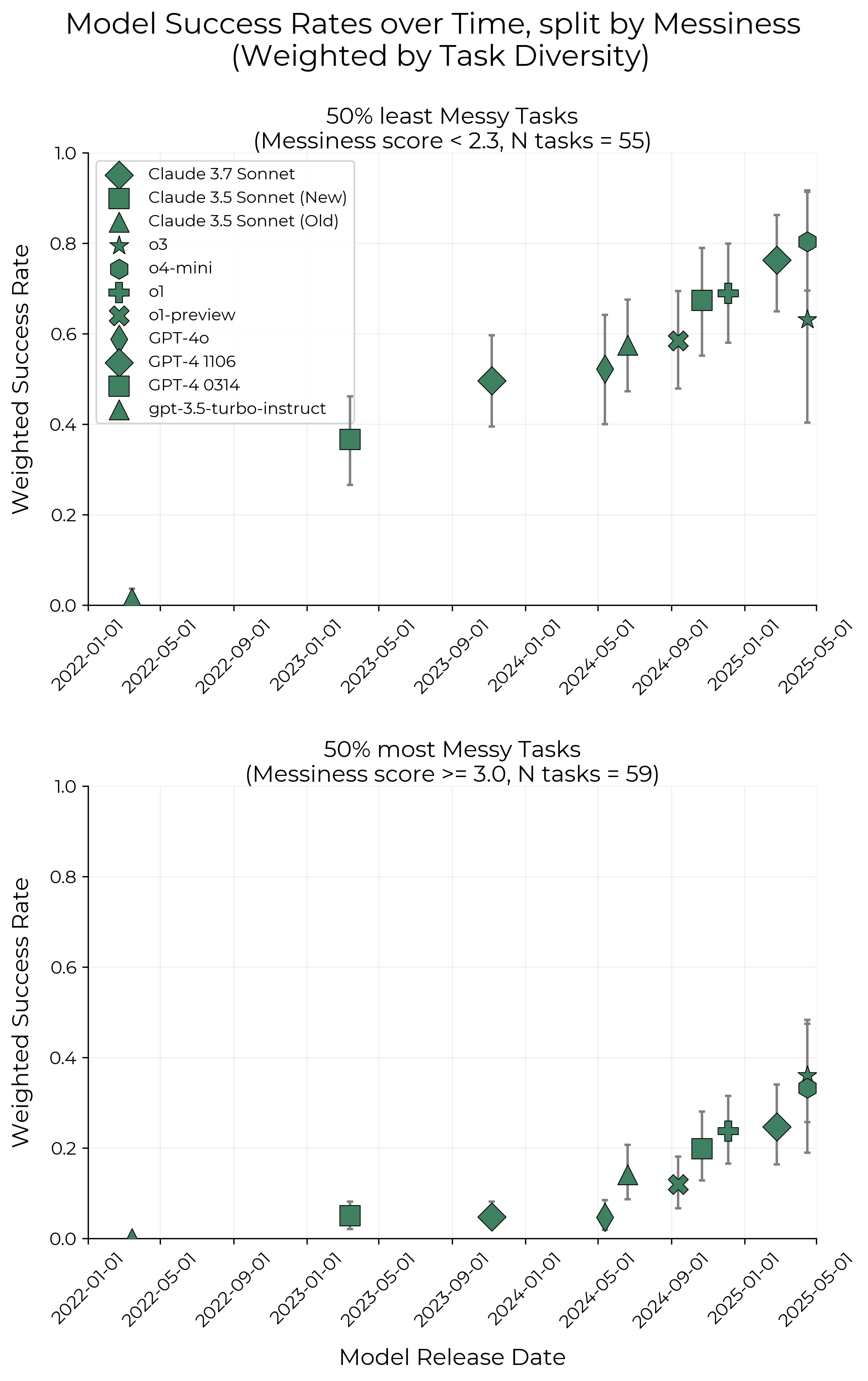
(4) 외부 타당성 및 SWE-bench Verified 결과: 연구팀은 SWE-bench Verified 벤치마크에서도 유사한 기하급수적 성능 향상 추세를 확인함. 다만, SWE-bench Verified의 경우 시간 지평이 약 70일마다 두 배로 짧게 나타남. 이는 해당 벤치마크의 인간 시간 추정 방식이 실제 현장 계약직 엔지니어의 시간 소요를 과소평가하여, AI 모델의 상대적인 시간 지평을 짧게 보이게 했을 가능성이 있음. 또한, 실제 내부 Pull Request (PR) 작업을 통한 실험에서는 저장소 관리자가 외부 계약자보다 5-18배 빠르게 문제를 해결함. AI 에이전트의 성능은 외부 계약자의 시간 소요와 더 잘 일치하는 경향을 보임. 이는 AI의 시간 지평이 낮은 맥락의 인간 노동과 더 잘 상응함을 시사함.
4. 결론 및 시사점
(1) AI 에이전트의 50% 작업 완료 시간 지평은 지난 6년간 약 7개월마다 두 배로 증가하는 기하급수적 추세를 보임. 이러한 발전은 AI의 신뢰성, 오류 적응력, 논리적 추론 및 도구 활용 능력의 향상에 기인함.
(2) 현재 추세가 지속되고 실제 소프트웨어 작업으로 일반화된다면, AI 시스템이 현재 인간에게 한 달이 걸리는 많은 소프트웨어 작업을 5년 내에 자동화할 역량을 갖출 것임. 이는 2028년 중반에서 2031년 중반 사이에, 1개월 (167시간) 지평의 AI가 등장할 것이라는 예측으로 이어짐. 특히 2024-2025년의 가속화된 추세를 반영하면 이 시기가 2027년 초로 더 앞당겨질 가능성도 있음.
(3) 교육 현장에서 AI 에이전트 설계 시 ‘정돈되지 않은’ 문제 해결 능력과 맥락 인지 능력을 높이는 데 초점을 두어야 함. AI의 오류 적응력, 논리적 추론 및 도구 활용 능력 향상이 중요한 학습 요소가 될 수 있음. 또한, AI 모델의 비용 효율성은 인간 전문가 대비 매우 낮아, 경제적 관점에서 AI 에이전트의 광범위한 활용 가능성을 열어 둠.
5. 리뷰어의 ADD(+) One: 생각 더하기
(1) 이 논문에서 가장 주목할 지점은 AI 역량 측정의 새로운 패러다임을 제시했다는 점임. 기존의 단편적인 벤치마크 점수나 특정 작업에서의 성공 여부는 AI의 실제적인 ‘유용성’을 판단하기에 충분하지 않음. 이 연구는 ‘인간이 얼마나 많은 시간을 들여 완료하는 작업인가?’라는 질문을 통해 AI의 능력을 우리 삶의 맥락과 직결시키는 강력한 접근 방식을 선보임. AI가 특정 작업을 50% 확률로 완료하는 데 걸리는 인간의 평균 시간을 ‘시간 지평’으로 정의함으로써, 우리는 AI가 인간의 노동 시장에 언제, 어떤 방식으로 영향을 미칠지에 대한 직관적이고 정량적인 예측 가능성을 확보함. 이는 단순한 기술 발전을 넘어 사회경제적 변화의 속도를 가늠하게 함.
(2) 이 연구가 명시하지 않은 더 넓은 의미는 ‘지식 노동 자동화’의 본질적 변화 시점을 포착하려 한다는 점임. 인지과학 관점에서 볼 때, 인간의 지식 노동은 단순 정보 처리뿐 아니라 문제 정의, 상황 판단, 오류 수정, 맥락 인지 등 복합적인 인지 과정을 포함함. 이 연구의 ‘시간 지평’ 개념은 AI가 이러한 복합적 인지 작업의 ‘길이’를 얼마나 따라잡고 있는지를 보여줌. 특히 ‘정돈되지 않은’ 작업과 ‘낮은 맥락’의 인간 노동에서 AI가 여전히 한계를 보인다는 점은, AI가 아직 복잡한 인간 사회의 암묵적 지식과 유연한 사고를 완전히 모방하지 못함을 의미함. 그럼에도 불구하고 성능 향상 추세가 유사하다는 점은, AI가 학습 데이터의 질과 양만 충분하다면 인간의 ‘상식’과 ‘직관’으로 여겨지던 영역까지 침투할 것임을 강력하게 시사함.
(3) 이 연구를 발전시킬 구체적인 아이디어는 교육 분야의 복합 과제에 대한 AI 시간 지평 측정 프레임워크를 개발하는 것임. 예를 들어, ‘학생의 학습 부진 원인 진단 및 맞춤형 피드백 제공’, ‘협력 학습 프로젝트 설계 및 갈등 중재’, ‘교실 수업 관찰 및 교사 전문성 발달 컨설팅’과 같은 고맥락, 다단계 교육 과제들을 정의하고, 이를 인간 전문가(교사, 교육 컨설턴트)가 수행하는 데 걸리는 시간을 측정함. 이 데이터를 바탕으로 AI 에이전트가 이러한 교육 과제를 얼마나 수행할 수 있는지 ‘교육 시간 지평’을 평가함. 이를 통해 AI를 활용한 교사 업무 보조, 학생 맞춤형 학습 관리, 교육 과정 설계 지원 등의 영역에서 AI의 실제 적용 가능성과 한계를 구체적으로 진단하고, AI 중심 교육 시스템으로의 전환 시점을 예측하는 데 활용할 수 있음.
6. 추가 탐구 질문
(1) AI의 ‘시간 지평’이 인간의 노동 시간과 같은 선형적 개념으로 측정되지만, AI의 학습 방식과 인지 오류 메커니즘은 인간과 근본적으로 다름. 그렇다면 AI가 특정 작업을 “완료”하는 과정에서 나타나는 ‘시간의 질’이나 ‘노동의 본질’이 인간과 어떻게 다른가? 이러한 질적 차이가 사회적 수용성이나 장기적인 경제적 가치 평가에 어떤 영향을 미치는가?
(2) 이 연구는 주로 소프트웨어 공학 및 기계 학습 연구 분야의 작업을 다룸. 만약 예술 창작, 의료 진단, 법률 자문, 심리 상담과 같이 창의성, 공감 능력, 윤리적 판단이 중요하게 작용하는 영역으로 AI의 시간 지평 개념을 확장한다면, 현재의 성장 추세는 유지될 수 있는가? 각 도메인의 ‘messiness’와 ‘맥락 의존성’이 AI의 시간 지평에 미치는 영향은 어떻게 달라지는가?
(3) AI의 시간 지평이 기하급수적으로 증가하여 인간의 장기 작업을 자동화하는 시점이 임박하고 있음. 이러한 기술 발전이 교육 시스템에 가져올 직업 교육의 변화, 평생 학습의 필요성 증대, 인간의 역할 재정의와 같은 거시적 변화에 대비하기 위한 교육 정책과 인프라 설계는 어떻게 이루어져야 하는가? 특히 교육 분야의 AI 개발자들에게 요구되는 윤리적 책임감과 사회적 영향력에 대한 질문은 무엇인가?
출처
- Kwa, T., West, B., Becker, J., Deng, A., Garcia, K., Hasin, M., … & Ziegler, D. M. (2025). Measuring AI Ability to Complete Long Software Tasks. arXiv preprint arXiv:2503.14499. https://arxiv.org/abs/2503.14499