
멀티모달 LLM은 성격 판단에서 편견을 넘어설 수 있는가
1. 연구의 목적
(1) 멀티모달 대규모 언어 모델(MLLM)은 AI 면접, 정신 건강 선별, 소셜 로봇 등 인간 중심의 중요 역할에 빠르게 투입됨. 이들 시스템의 핵심은 ‘성격 인식’ 능력임. 그러나 기존 벤치마크는 Big Five 성격 점수 예측에만 초점을 맞춤. 모델이 관찰 가능한 행동을 진정으로 이해해서 성격을 인식하는지, 아니면 피상적인 패턴 매칭으로 ‘편견’을 갖는지는 파악하기 어려움. EU AI Act 등 최근 규제는 고위험 AI 시스템에 대해 모든 예측에 대한 설명 가능한 증거 경로를 의무화함. 이는 AI의 성격 판단이 신뢰성을 확보하기 위해 필수적임.
(2) 이 연구는 AI의 성격 인식 능력에 대한 간극을 해소하고자 함. MLLM이 단순히 성격 점수를 ‘맞추는’ 것을 넘어, 그 판단을 관찰 가능한 행동 증거에 연결하여 설명하는 능력을 검증하는 데 목표를 둠. 이를 위해 근거 기반 성격 추론(Grounded Personality Reasoning, GPR)이라는 새로운 과제를 공식화하고, 이를 평가할 다층적인 MM-OCEAN 데이터셋과 포괄적인 벤치마크를 구축함.
2. 연구의 방법
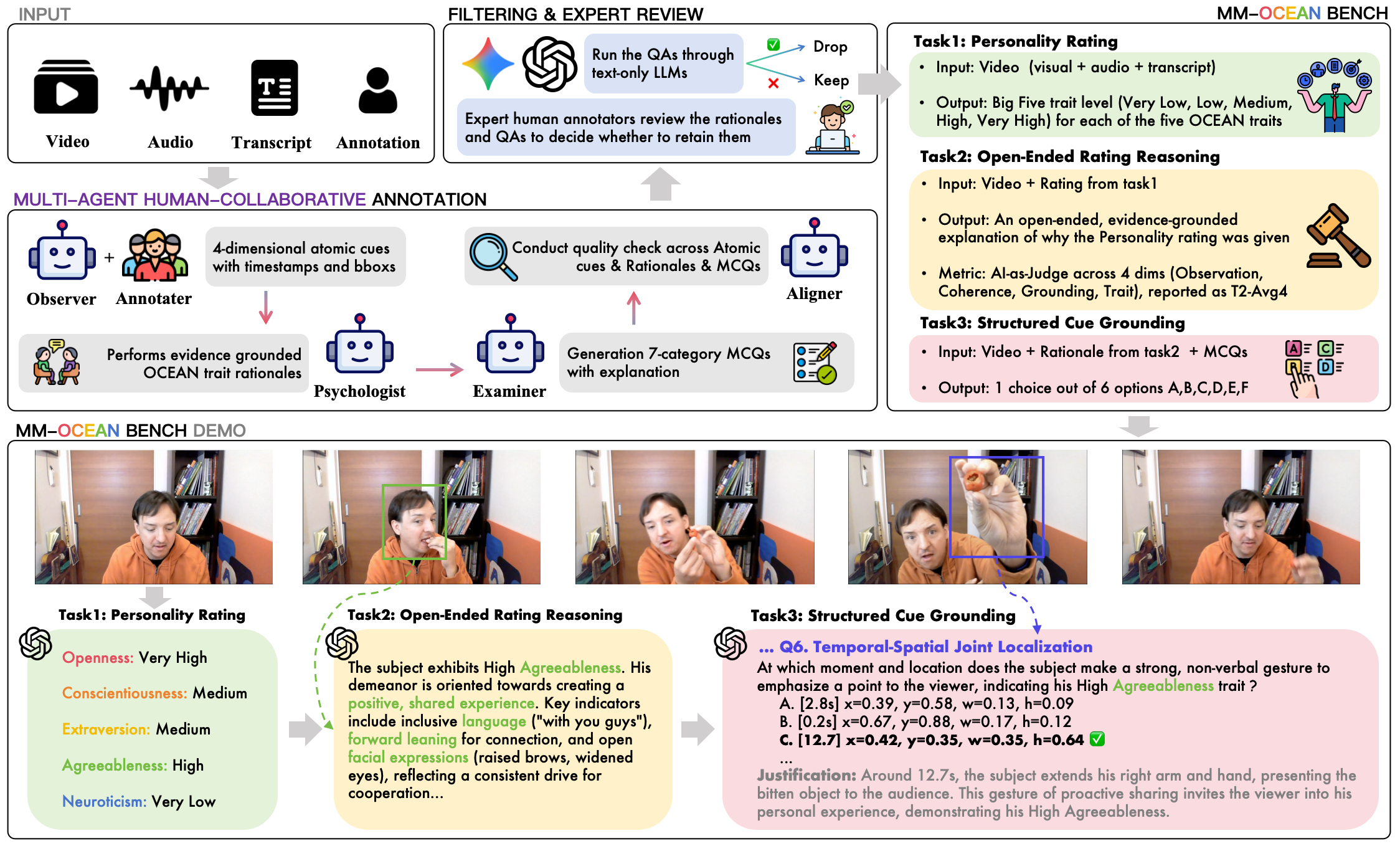
(1) 이 연구는 MLLM의 성격 판단 과정이 단편적인 예측에 그치는지, 아니면 논리적 추론과 관찰 기반의 근거 제시를 포함하는지를 평가하는 데 중점을 둠. 이를 위해 MLLM이 (1) 미세한 멀티모달 행동 단서를 정확히 인식하고, (2) 이 단서들이 성격 특성과 어떻게 연결되는지 근거 기반으로 추론하며, (3) 특정 하위 기술을 측정하는 구조화된 객관식 질문으로 이러한 능력을 입증하도록 요구하는 근거 기반 성격 추론(GPR) 프레임워크를 개발함.
(2) 연구는 다음 요소를 중심으로 수행됨.
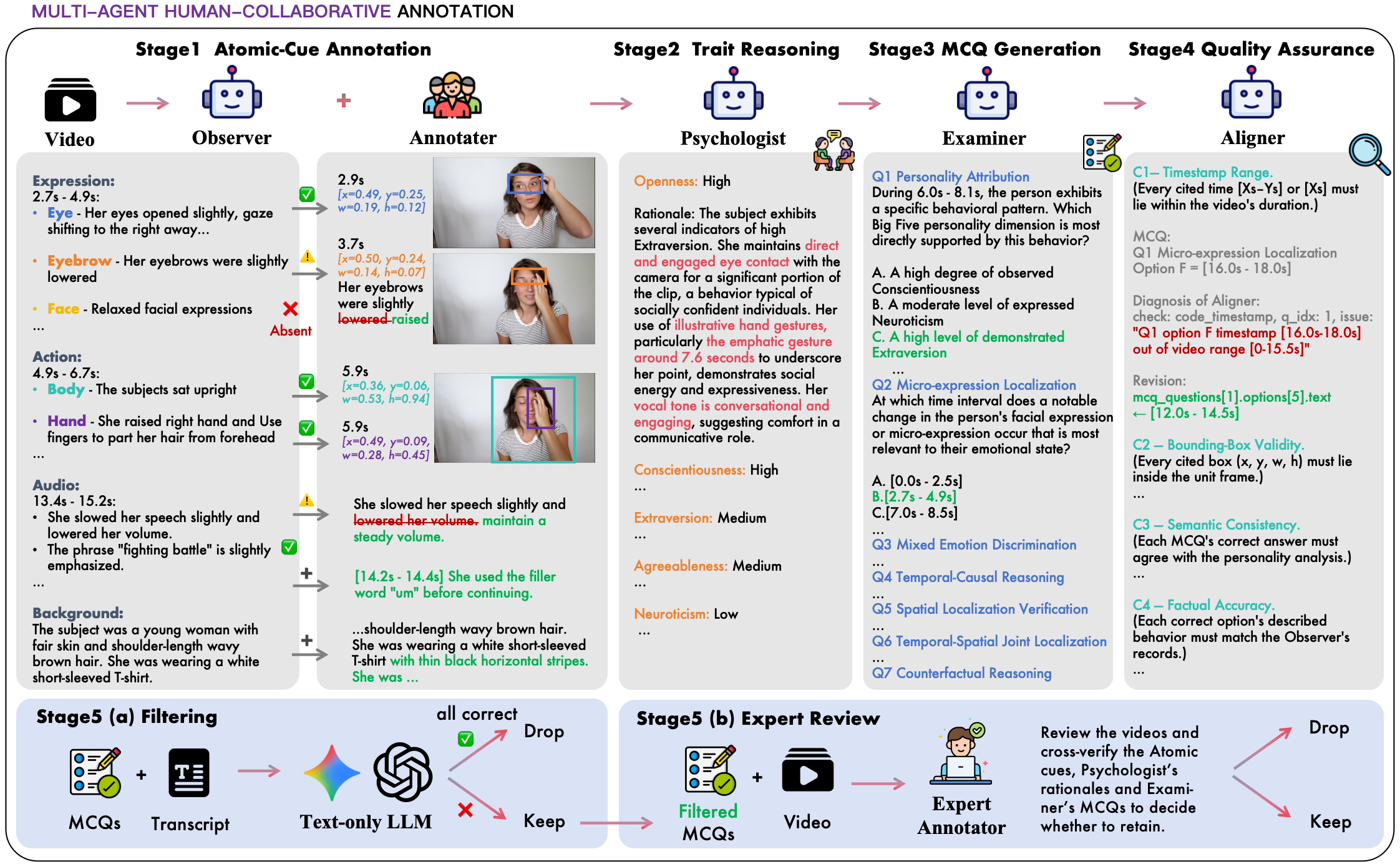
- MM-OCEAN 데이터셋: 1,104개의 단일 화자 비디오와 5,320개의 근거 제시 객관식 질문(MCQ)으로 구성된 새로운 데이터셋을 구축함. 이는
관찰자(Observer),심리학자(Psychologist),평가자(Examiner),정렬자(Aligner)라는 4가지 LLM 에이전트와 인간의 검증이 결합된 5단계의멀티 에이전트-인간 협업 주석 파이프라인으로 제작됨. - 3단계 평가 프레임워크: MLLM의 성격 인식 사슬을 깊이 있게 분석하고자 (1)
서수 성격 평가(Ordinal Personality Rating, T1), (2)개방형 평가 추론(Open-Ended Rating Reasoning, T2), (3)구조화된 단서 근거 제시(Structured Cue Grounding, T3)의 세 가지 작업을 설계함. - 4가지 샘플 수준 실패 모드 지표: 집계된 작업 점수가 아닌, 각 샘플에서 어떤 단계가 실패했는지 파악하기 위해
편견율(Prejudice Rate, PR),조작율(Confabulation Rate, CR),통합 실패율(Integration-failure Rate, IR),총체적 근거 제시율(Holistic-Grounding Rate, HR)을 도입함. - 벤치마크 대상: 13개의 비공개(closed-source) 모델과 14개의 공개(open-source) 모델을 포함한 총 27개의 대표적인 MLLM을 평가하고 비교함.
3. 주요 발견
이 연구는 기존 성격 평가 벤치마크의 한계를 넘어, MLLM이 성격 판단에 이르는 과정을 다층적으로 분석하고 ‘편견 간극’이라는 중요한 문제를 밝혀냄.
(1) 근거 기반 성격 추론(GPR) 프레임워크: 기존의 성격 인식 연구가 Big Five 점수 예측이라는 ‘무엇’에만 집중했다면, GPR은 ‘왜’ 그런 판단이 나왔는지를 검증하는 새로운 패러다임을 제시함. 이 프레임워크는 MLLM이 (1) 비디오에서 관찰 가능한 미세한 행동 단서를 포착하고, (2) 이 단서를 바탕으로 성격 특성을 추론하며, (3) 그 추론을 다시 실제 단서에 연결하여 설명하는 평가-추론-근거 제시의 연쇄 과정을 요구함. 이는 AI 시스템의 신뢰성과 투명성을 확보하는 데 필수적인 능력으로 간주됨.
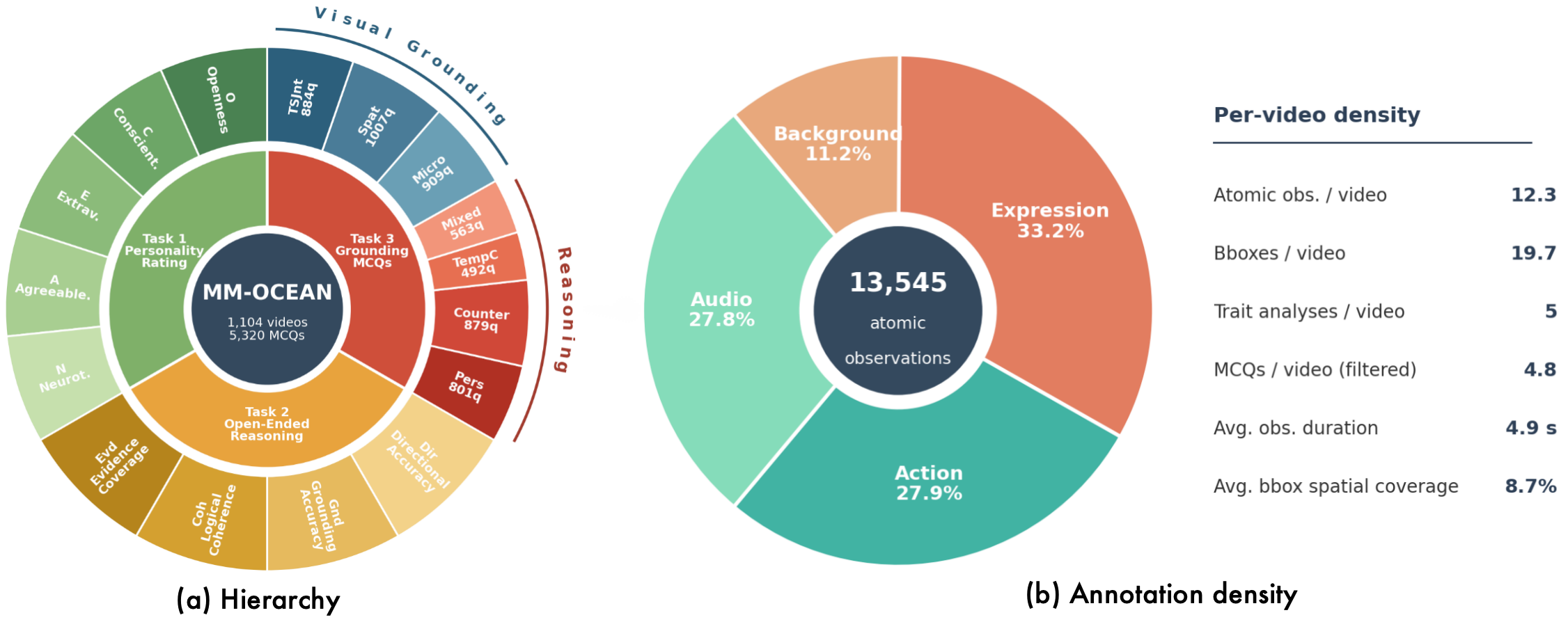
(2) MM-OCEAN 데이터셋의 다층적 구조: 이 연구는 GPR 평가를 위해 MM-OCEAN이라는 고유한 데이터셋을 구축함. 1,104개의 15초짜리 영어 단일 화자 비디오에 대해 다음 세 가지 층위의 정밀한 주석을 제공함.
- 원자적 행동 관찰: 표정, 행동, 오디오, 배경이라는 4가지 지각 채널에서 시간 정보(timestamp)와 공간 정보(bounding box)가 포함된 13.5K개 이상의 미세 행동 단서가 인간 전문가의 검증을 거쳐 주석화됨. 이는 모델이 실제로 무엇을 보고 판단했는지 추적하는 기초 자료가 됨.
- 성격 특성 분석: Big Five 각 특성에 대해 전문가가 판단한 성격 수준과 함께, 그 판단을 뒷받침하는 구체적인 행동 단서(위의 원자적 행동 관찰)와 추론 과정이 상세히 기술됨.
- 단서 근거 제시 객관식 질문(MCQ): 모델이 특정 행동 단서에 대한 이해와 추론 과정을 얼마나 잘 연결하는지 평가하기 위해, 7가지 인지 범주(예: 성격 귀인, 반사실적 추론, 시공간적 공동 위치 파악 등)에 걸쳐 5,320개의 객관식 질문이 생성됨.
(3) ‘편견 간극(Prejudice Gap)’의 발견: 27개 MLLM을 벤치마킹한 결과, 대다수 모델에서 ‘편견 간극’이라는 현상이 드러남. 이는 MLLM이 정답을 맞혀도 틀린 이유로 맞추는 경향을 나타냄.
- 높은 편견율(PR): 평균적으로 올바른 성격 평가(T1) 중 51%가 실제 관찰 가능한 행동 단서에 근거하지 않음. 이는 모델이 피상적인 패턴에 의존하여 정답을 맞출 가능성이 높음을 시사함. 가장 좋은 성능을 보인 모델도 15% 정도의 편견율을 보임.
- 낮은 총체적 근거 제시율(HR): 평가, 추론, 근거 제시 세 가지 모두 정확한 총체적 근거 제시율(HR)은 평균 10.4%에 불과하며, 최고 모델인 Gemini 3 Flash도 33.5%에 그침. 이는 MLLM이 성격 판단에 필요한 종합적인 능력이 아직 미흡함을 단적으로 보여줌.
- 시각적 근거 제시 능력의 병목 현상: 독점 모델과 공개 모델 간 성능 차이는
평가(T1)와추론(T2)에서는 작지만,단서 검색(T3)에서는 공개 모델이 평균 26.6% 낮음. 특히미세 표정(Micro-expression)탐지,공간적 위치 파악(Spatial Localization),시공간적 공동 위치 파악(Temporal-Spatial Joint Localization)과 같은 시각적 근거 제시 범주에서 가장 큰 격차를 보임. 이는 MLLM이 복잡한 시각 정보를 세밀하게 이해하고 특정 행동 단서에 연결하는 능력이 여전히 핵심적인 병목 지점임을 시사함.
(4) 모델 유형별 진단: 모델의 평가-근거 제시 불일치(Rating-Grounding Misalignment, RGM) 지표를 통해 두 가지 아키타입이 명확히 구분됨.
- 자신감 있는 평가자(Confident Raters):
라마-4-마베릭(Llama-4-Maverick-FP8)과 같은 모델은 T1 평가 점수는 높지만, 그 평가를 뒷받침하는 T2(추론)와 T3(근거 제시)에서 실패하는 경향을 보임. 이들은 근거가 약해도 확신에 찬 판단을 내리는 특성을 가짐. - 신중한 추론가(Cautious Reasoners):
제미니 2.5 플래시(Gemini 2.5 Flash)와 같은 모델은 T1 평가 점수는 낮지만, T2와 T3에서 강점을 보이며, 신중하게 추론하고 근거를 제시하는 모습을 보임.
4. 결론 및 시사점
(1) 이 연구는 MLLM의 성격 인식 능력에 대한 기존의 평가 방식이 편견 간극(Prejudice Gap)을 간과하고 있음을 명확히 입증함. 단순히 성격 점수를 ‘맞추는’ MLLM의 능력은 과대평가되었으며, 실제 관찰 가능한 행동에 근거하여 판단을 추론하고 연결하는 근거 기반 추론 능력은 여전히 낮은 수준임. MLLM은 종종 ‘올바른 점수를 잘못된 이유로 얻음’이 확인됨.
(2) 교육 현장에 주는 시사점:
- AI 판단의 신뢰성 재고: 교육 현장에서 MLLM을 학생 평가, 상담 지원, 개인화된 학습 경험 제공 등 인간의 성격이나 행동을 판단하는 중요한 역할에 활용할 때, 단순히 AI의 점수가 높다고 해서 맹목적으로 신뢰해서는 안 됨. AI가 어떤 구체적인 행동 단서를 기반으로 판단을 내렸는지 설명 가능한 과정이 필수적임.
Prejudice Gap은 AI의 판단이 그 자체로 ‘진실’이 아님을 말함. - AI 리터러시 교육의 심화: 교사와 학생 모두 AI가 제시하는 정보의
근거를 비판적으로 검증하는AI 리터러시 역량을 길러야 함. 특히 표정, 음성 톤, 몸짓과 같은 미세 행동 단서에 기반한 AI의 판단은 더욱 세심한 검토가 필요함. AI의 판단이 왜곡된 편견일 수 있음을 인지하는 것이 AI 시대 교육의 핵심 과제 중 하나임. - 인간 교사의 역할 재정립: MLLM이 인간 행동을 정확히 이해하고 추론하는 데 한계를 보임에 따라, 맥락적 이해, 공감, 윤리적 판단 등 인간 교사 고유의 역할과 전문성이 더욱 강조됨. AI는 보조 도구로 활용되되, 최종적인 판단과 책임은 여전히 인간에게 있음을 명확히 해야 함.
(3) AI 설계에 주는 시사점:
- 행동 근거 제시 능력 우선 개선: 차세대 MLLM은 단순히 성능 점수를 높이는 것을 넘어,
시공간적으로 세밀한 행동 단서에 대한 이해와 이를추론에 연결하는 능력을 최우선으로 개선해야 함. 특히미세 표정,신체 부위의 공간적 위치 파악과 같은시각적 근거 제시능력이 현재 MLLM의 핵심 병목 지점임. 이는 MLLM의 후처리 훈련(post-training) 과정에서 집중적으로 다뤄져야 할 영역임. - 설명 가능한 AI(XAI) 원칙의 내재화: MLLM 개발 과정에서부터 추론의 투명성과 근거 제시 능력을 핵심 평가 지표로 삼아야 함. EU AI Act와 같은 규제 환경은 AI의 설명 가능성을 의무화하고 있으며, 이 연구는 신뢰할 수 있는
성격 인식 MLLM개발을 위한 실질적인 로드맵을 제공함.
5. 리뷰어의 ADD(+) One: 생각 더하기
(1) 이 논문에서 가장 주목할 지점은 MLLM의 성격 인식 능력에 대한 평가에서 Prejudice Gap이라는 현상을 명확히 정의하고 측정했다는 점임. 기존 연구가 AI의 ‘정답률’이라는 표면적 성과에 집중했다면, 이 연구는 “모델이 정답을 맞췄더라도 잘못된 근거로 맞출 수 있다”는 본질적인 문제를 날카롭게 파고듦. 이는 신뢰할 수 있는 AI를 위한 핵심 질문인 설명 가능성과 투명성을 실증적으로 드러낸 성과임. 특히 AI를 교육 현장에 도입하려는 우리에게, AI의 판단 결과를 맹목적으로 수용해서는 안 되며, 그 근거를 비판적으로 검증해야 한다는 강력한 경고 메시지를 전달함. 단순히 높은 점수만 보고 AI를 전적으로 신뢰하는 태도는 결국 ‘편견’이 만든 AI의 ‘오판’을 그대로 수용하는 결과를 낳을 수 있음.
(2) 이 연구는 AI 분야를 넘어 더 넓은 의미를 지님. 인지과학적 관점에서 보면, 인간의 초두 효과(first impression)와 확증 편향이 MLLM에서도 유사하게 나타날 수 있음을 시사함. 모델이 영상 초반의 피상적인 단서에 과도하게 의존해 성격 판단을 내리고, 이후의 미세한 행동 단서는 무시하는 경향이 있을 수 있음. 이는 AI가 인간의 인지적 오류를 답습할 수 있다는 점을 보여줌. 교육철학적 측면에서는, AI의 ‘판단’이 단순히 데이터 패턴 학습의 결과물일 뿐, 인간과 같은 ‘진정한 이해’나 ‘공감’에 기반하지 않을 수 있다는 점을 상기시킴. 이는 AI가 교사의 역할을 보조하거나 대체할 때, 인간 교사의 윤리적 판단, 현장 맥락에 대한 깊은 이해, 그리고 학생에 대한 개별적인 공감이 여전히 대체 불가능한 영역임을 강조하는 강력한 근거가 됨.
(3) 이 연구를 발전시킬 구체적인 아이디어는 다음과 같음. 첫째, Prejudice Gap의 개념을 활용한 AI 윤리 및 비판적 활용 교육 프로그램을 개발하는 방안을 제안함. AI가 학생의 행동을 “내성적”이라고 판단했으나, 그 근거를 파고들어 보니 실제 행동 단서가 아닌 AI의 ‘편견’이었음을 확인하는 시뮬레이션 기반 워크숍을 교사들에게 제공함. 이를 통해 AI 판단의 맹점을 직접 경험하고, 비판적 검토 능력을 함양하게 함. 둘째, 교사가 학생 행동 비디오를 업로드하면 MLLM이 GPR 프레임워크에 따라 성격 특성 예측과 함께 근거가 되는 행동 단서와 추론 과정을 시각적으로 제시하고, 교사가 이를 검토 및 수정할 수 있는 인간-AI 협업 성격 평가 도구를 개발함. 특히 T3의 Temporal-Spatial Joint Localization 능력을 활용해, 중요한 행동이 발생한 영상의 특정 시점과 해당 행동이 나타나는 바운딩 박스를 직접 제시하여 교사가 AI의 판단 근거를 직관적으로 이해하고, 필요한 경우 자신의 전문성을 바탕으로 개입하도록 하는 협력적 모델을 구축함.
6. 추가 탐구 질문
(1) 문화적 배경이나 언어가 다른 다국어 환경에서 MLLM의 성격 인식 편견 간극은 어떻게 다르게 나타날까? 비서구권 문화권의 미세 행동 단서나 비언어적 표현에 대한 이해 부족은 모델의 Prejudice Gap을 더욱 심화시킬 가능성이 있음.
(2) MLLM이 교육 현장에서 학생의 학습 스타일, 참여도, 또는 학업 성취 예측과 같은 비인지적 특성을 평가할 때, 이 연구에서 발견된 편견 간극이 학습 효과 예측의 정확성이나 개인화된 교육 추천의 공정성에 어떤 영향을 미칠까?
(3) MLLM의 근거 제시 능력이 향상되어 모든 판단에 대한 명확한 행동 근거를 제시할 때, 이는 인간의 자기 성찰 과정에 어떤 영향을 미치며, AI가 제시하는 근거가 오히려 인간의 확증 편향이나 고정관념을 강화할 윤리적 위험은 없을까?
출처
- Kang, C., Yan, T., Gong, S., Zhang, M., Ouyang, L., Liu, R., Zheng, B., Lu, H., Zhang, K., Sato, Y., & Huang, Y. (2026). Perception or Prejudice: Can MLLMs Go Beyond First Impressions of Personality?